
第六章 存储器层次结构
第六章 存储器层次结构
6.1 存储技术
6.1.1 随机访问存储器 RAM
静态随机访问存储器 SRAM
存储单元具有双稳态(bistable)特性,抗干扰能力强
动态随机访问存储器 DRAM (比SRAM慢)
用一个很小的电容的充放电来存储位,容易因为电压干扰放电而丢失保存的信息
下图是 SRAM 和 DRAM 的一个对比:

- 传统的 DRAM
DRAM 芯片中有许许多多的超单元(supercell),假设有 $d$ 个超单元,每个超单元由 $w$ 个 DRAM 单元组成,每个 DRAM 单元可以存储一个位,那么这块芯片就可以存储 $d*w$ 个位
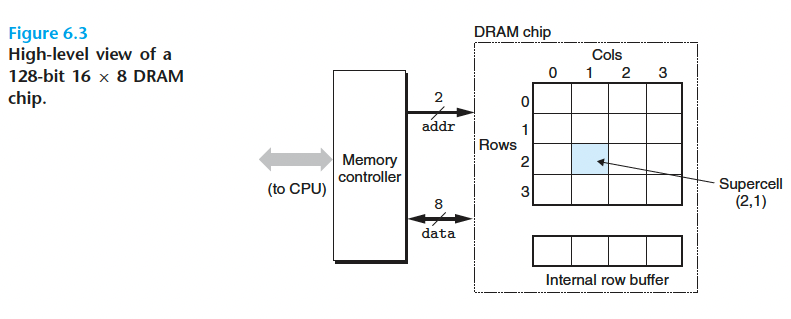
上图中的蓝色阴影就是一个超单元,它的坐标是 $(2,1)$ ,每个超单元里有 8 个DRAM单元,所以这是一个能够存储 $16*8=128$ 位的 DRAM 芯片
- 内存模块(memory module)
Practice Problem 6.1
| Organization | r | c | $b_r$ | $b_c$ | $max(b_r,b_c)$ |
|---|---|---|---|---|---|
| 16*1 | 4 | 4 | 2 | 2 | 2 |
| 16*4 | 4 | 4 | 2 | 2 | 2 |
| 128*8 | 16 | 8 | 4 | 3 | 4 |
| 512*4 | 32 | 16 | 5 | 4 | 5 |
| 1024*4 | 32 | 32 | 5 | 5 | 5 |
- 增强的 DRAM
- 快页模式 DRAM (fast page mode DRAM, FPM DRAM)
- 扩展数据输出 DRAM (Extended Data Out DRAM, EDO DRAM)
- 同步 DRAM (Synchronous DRAM, SDRAM)
- 双倍数据速率同步 DRAM (Double Data-Rate Synchronous DRAM, DDR SDRAM)
- 视频 RAM(Video RAM, VRAM)
- 非易失性存储器
- PROM (Programmable ROM) 只能被编程一次
- EPROM (Erasable Programmable ROM)
- EEPROM (Electrically Erasable PROM) 电子可擦除 PROM
- Flash Memory 闪存
如果断电,SRAM 和 DRAM 都会丢失信息,所以它们是易失的(volatile)
于此相对的,非易失性存储器(nonvolatile memory)断电后也不会丢失信息,这类存储器统称为 ROM (Read-Only Memory)
固态硬盘(Solid State Disk, SSD)就是基于闪存做的
- 访问主存
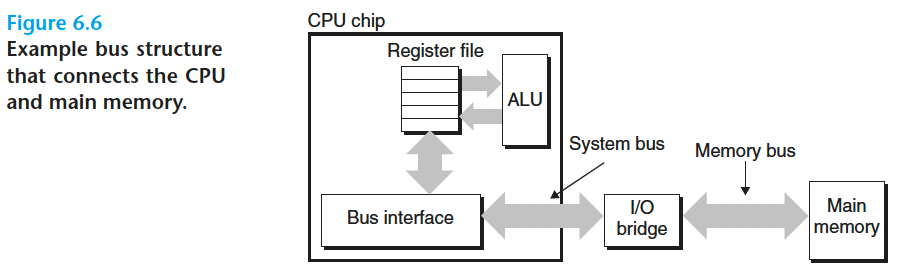
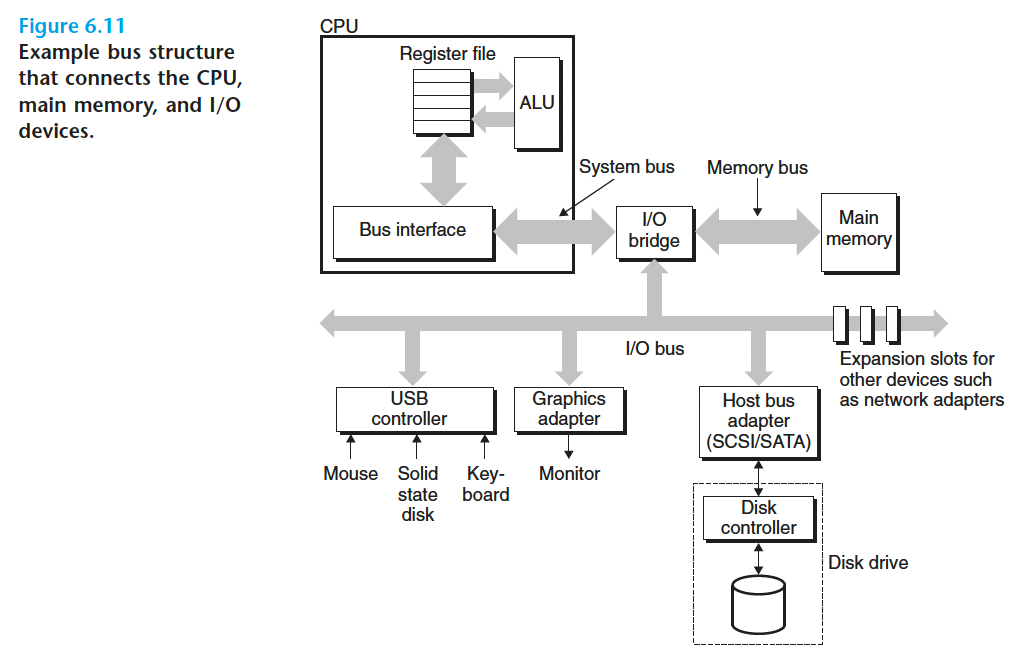
数据流通过称为总线 (bus)的共享电子电路在处理器和 DRAM 主存之间来来回回 。
连接CPU和主存的总线结构示意图:
6.1.2 磁盘存储
1.磁盘构造
磁盘由盘片(platter)构成。每个盘片有表面(surface),上面覆盖着磁性材料。盘片中间有个旋转主轴(spindle),它使得盘片以固定的旋转速率(rotational rate)旋转。
这是一个典型的盘片表面的结构:
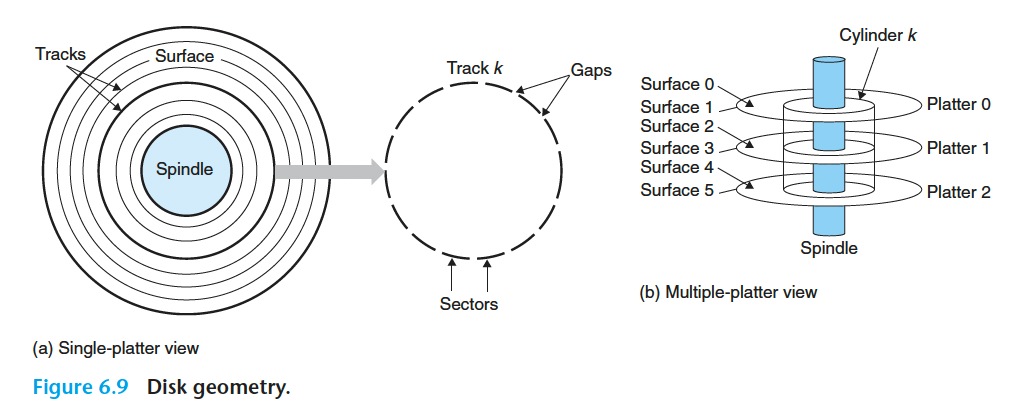
每个表面由一组称为磁道(track)的同心圆组成。每个磁道被划分为一组扇区(sector)。扇区之间有一些间隙(gap)分隔开,间隙不存储数据位。
2.磁盘容量
磁盘的最大容量由以下因素决定:
- 记录密度(recording density):磁道一英寸的段中可以放入的位数
- 磁道密度(track density):
- 面密度(areal density):记录密度与磁道密度的乘积
3.磁盘操作
磁盘用读写头(read/write hand)来读写磁性表面的位。
读写头靠传动臂驱动。
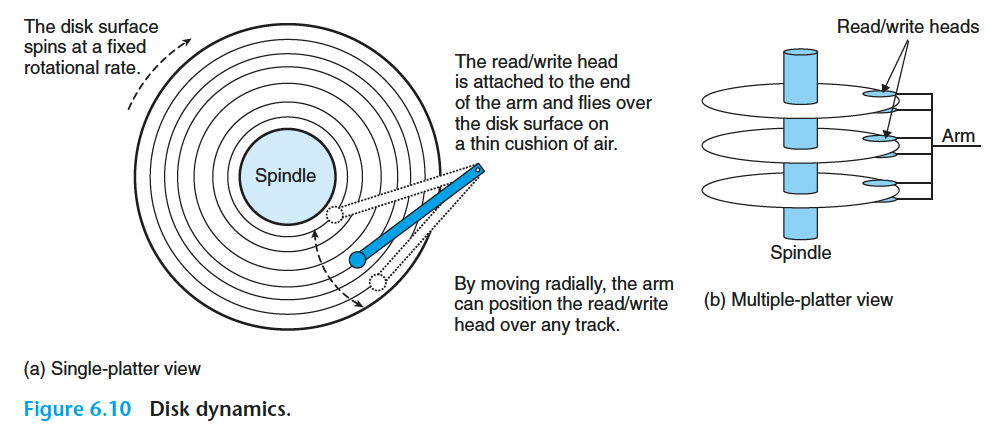
磁盘以扇区大小的块来读写数据。
对扇区的访问时间由三个主要部分组成:寻道时间 $T_{seek}$(seek time)、旋转时间 $T_{rotation}$(rotational latency)和传送时间 $T_{transfer}$(transfer time)
Practice Problem 6.3
Estimate the average time (in ms) to access a sector on the following disk:
| Parameter | Value |
|---|---|
| rotational rate | 12,000 RPM |
| $T_{avg seek}$ | 5 ms |
| Average number of sectors/track | 300 |
4.逻辑磁盘块
通过前面的内容可以看到现代磁盘的结构比较复杂,为了向操作系统隐藏这一复杂性,做了一个抽象。
对于操作系统,磁盘抽象为一个简单的扇区序列。例如,一共有B个扇区,则操作系统看到的就是编号为$0,1,…,B-1$ 的扇区序列。
磁盘控制器负责维护抽象的扇区号与实际物理扇区之间的映射关系。
5.连接 I/O 设备
6.访问磁盘
direct memory access (DMA)
CPU发出读磁盘的指令,磁盘控制器负责读磁盘并把读出的内容送进主存,然后磁盘控制器通过中断的方式通知CPU读磁盘的操作已经完成。
6.1.3 固态硬盘
Solid State Disk,SSD
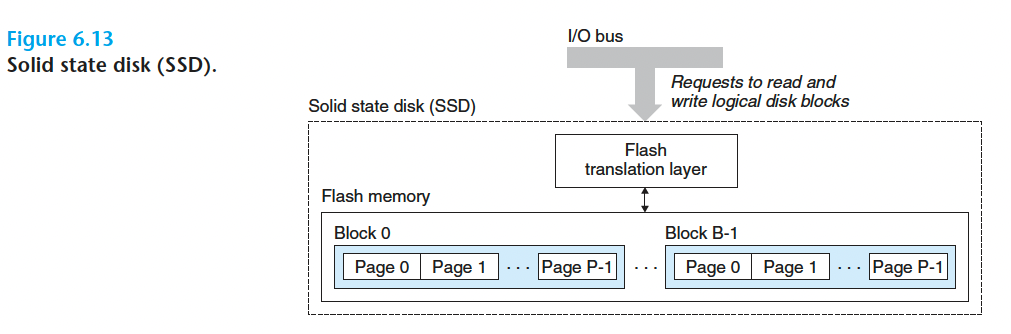
Flash translation layer 就相当于机械硬盘中的磁盘控制器,负责逻辑地址和SSD实际物理地址的映射
一个闪存由 B 个块的序列组成,每个块由P页组成。 通常,页的大小是512字节~4KB, 块是由32~128页组成的
数据以页为单位读写
Practice Problem 6.5
As we have seen, a potential drawback of SSDs is that the underlying flash memory can wear out.
For example, for an SSD, Intel guarantees about 128 petabytes ($128\times10^{15}$ bytes) of writes before the drive wears out. Given this assumption, estimate the lifetime (in years) of this SSD for the following workloads:
A. Worst case for sequential writes: The SSD is written to continuously at a rate of 470 MB/s.
B. Worst case for random writes: The SSD is written to continuously at a rate of 303 MB/s
C. Average case: The SSD is written to at a rate of 20 GB/day
6.2 局部性 Locality
一个编写良好的计 算 机 程序常常具 有良好的局部性 Clocality) 。也就是,它们倾向于引用邻近于其他最近引用过的数据项的数据项,或者最近引用过的数据项本身。这种倾向 性,被称为局部性原理 (principle of locality), 是一个持久的概念
- 时间局部性(temporal locality):被引用过一次的内存位置很可能在不远的将来再被多次引用
- 空间局部性(spatial locality):如果一个内存位置被引用了 一次,那么程序很可能在不远的将来引用附近的一个内存位置。
6.3 存储器层次结构 memory hierarchy
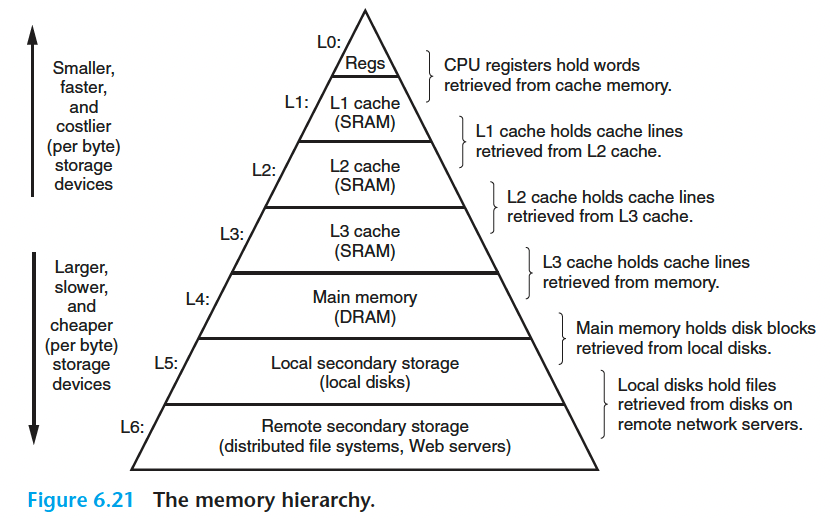
从这个金字塔由下往上,访问存储器的速度越来越快,每比特存储器的成本越高
6.3.1 存储器层次结构中的缓存
高速缓存 (cache 读作 “cash”)
1.缓存命中(cache hit)
当程序需要第 k+ 1 层的某个数据对象 d 时,它首先在当前存储在第 k 层的一个块中查找 d 。如果 d 刚好缓存在第 k 层中,那么就是我们所说的缓存命中
2.缓存不命中(cache miss)
另一方面,如果第 k 层中没有缓存数据对象 d, 那么就是我们所说的缓存不命中
当发生缓存不命中时,第 k 层的缓存从第 k + 1 层缓存中取出包含 d 的那个 块,如果第 k 层已经满了,可能就会覆盖现存的一个块。
3.缓存不命中的种类
第一种情况,第 k 层缓存是空的。这时对 k 层的任何访问都不命中。
空缓存也称为冷缓存(cold cache),这种不命中称为强制性不命中(compulsory miss)或 cold miss
使用一段时间后,存储器得到热身(warmed up),cold miss 就不会发生了
第二种情况,冲突不命中(conflict miss)。和存储器的放置策略有关
第三种情况,容量不命中(capacity miss)。和存储器的大小有关
4.缓存管理

6.4 高速缓存存储器
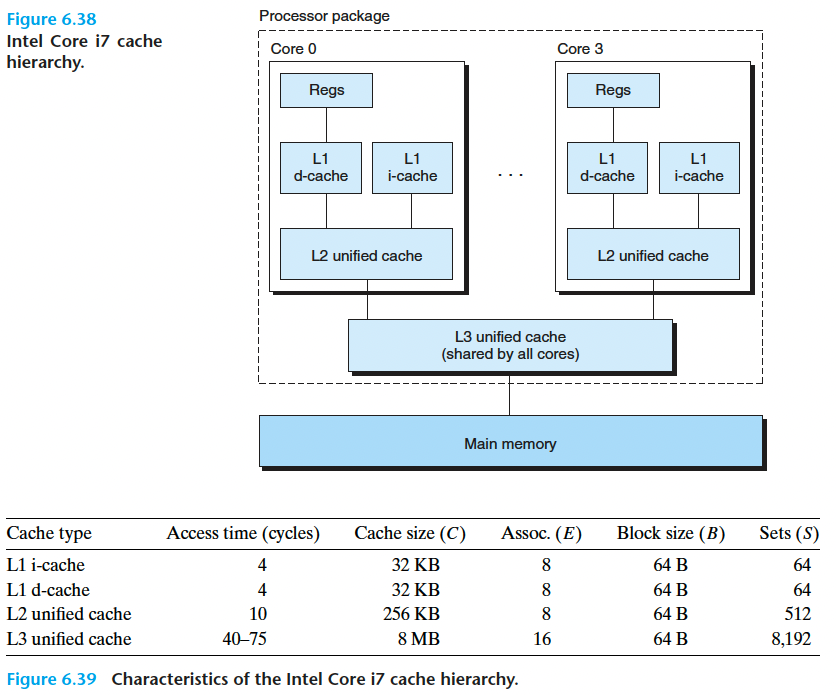
早期的计算机存储器层次结构只有三层:CPU寄存器、DRAM主存 和 磁盘
但是随着 CPU 制造技术的飞速进步,CPU和主存之间的 速度差距越来越大,所以系统设计者被迫在 CPU寄存器和主存之间插入了一个 SRAM cache,称为 L1 高速缓存。后来又因为同样的原因,又插入了 L2 缓存和 L3 缓存
6.4.1 通用的高速缓存存储器的组织结构
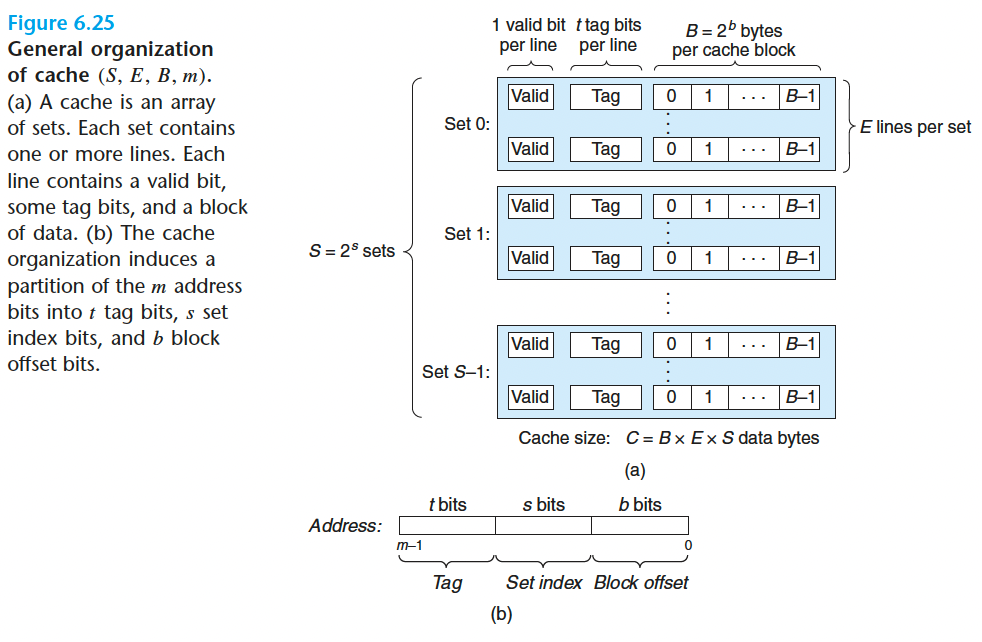
在上图中,存储器地址有 $m$ 位,形成 $M=2^m$ 个不同的地址。
这样一个机器的高速缓存被组织成一个有 $S=2^s$ 个高速缓存组 (cache set)的数组。每个组包含 $E$ 个高速缓存行(cache line)。
每个缓存行由 $B=2^b$ 个数据块(block)、一个有效位(valid bit)和 $t$ 个能唯一标识此行中数据块的标记位(tag bit)组成。
Practice Problem 6.9
The following table gives the parameters for a number of different caches. For each cache, determine the number of cache sets (S), tag bits (t ), set index bits (s), and block offset bits (b).
| Cache | m | C | B | E | S | t | s | b |
|---|---|---|---|---|---|---|---|---|
| 1 | 32 | 1024 | 4 | 1 | 256 | 22 | 8 | 2 |
| 2 | 32 | 1024 | 8 | 4 | 32 | 24 | 5 | 3 |
| 3 | 32 | 1024 | 32 | 32 | 1 | 27 | 0 | 5 |
6.4.2 直接映射的高级缓存
在6.4.1中,如果缓存的每个内存组只有1行,即 $E=1$ ,那么这就叫做直接映射的高级缓存(direct-mapped cache)
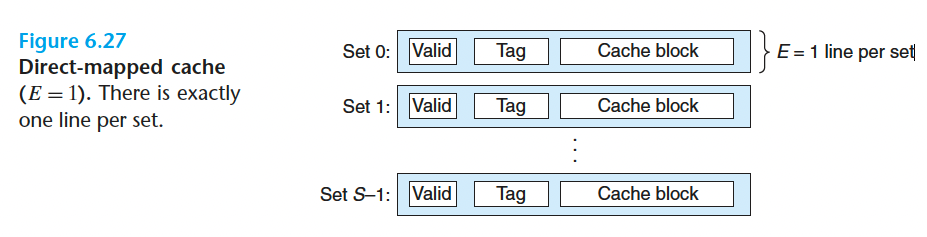
从这样的高级缓存里读一个字分为3步:1)组选择;2)行匹配;3)字抽取。
1.组选择
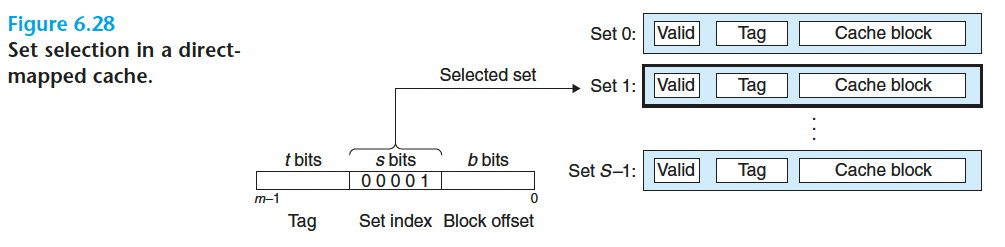
在这一步中,高速缓存从 w 的地址中间抽取出 s 个组索引位并用它标识组号。
2.行匹配
在第一步中已经匹配了某个组,而且现在这个组里只有一行。如果这一行的有效位设置了,而且 tag 位和地址中的相同,那么这一行里就存在想要的字的副本。
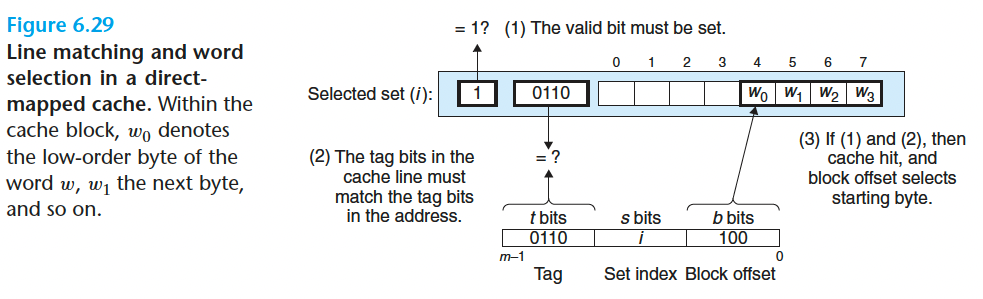
3.字选择
确定了字所在的行后,地址中的 b 位组偏移位指示了该字的第一个字节的偏移量。这样就能够得到这个字了。
4.不命中时的行替换
如果缓存不命中,那么它需要从存储器层次结构中的下一层取出被请求的块 ,然后将新的块存储在组索引位指示的组中的一个高速缓存行中。
5.综合:运行中的直接映射高速缓存
6.冲突不命中
Practice Problem 6.11
假想一个高速缓存,用地址的高 s 位做组索引,那么内存块连续的片 (chunk)会被映射到同一个高速缓存组 。
A. 每个这样的连续的数组片中有多少个块?
$2^t$ 个
B. 考虑下面的代码,它运行在一个高速缓存形式为 (S, E, B, m)=(512, 1, 32, 32) 的系统上:
1 | int array[4096]; |
在任意时刻,存储在高速缓存中的数组块的最大数量为多少?
32个块
6.4.3 组相联高速缓存
$1<E<\frac{C}{B}$
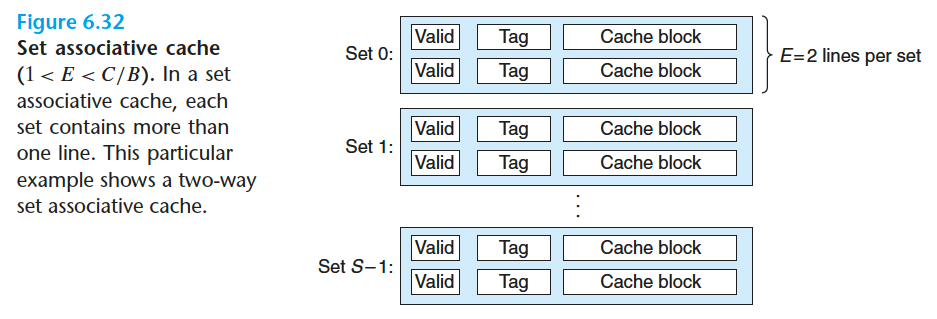
1.组选择(和之前一样)
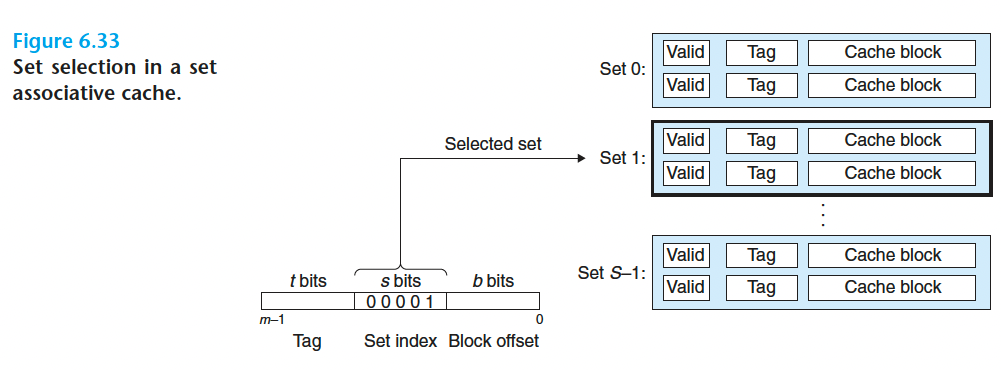
2.行匹配和字选择
要匹配 tag 位
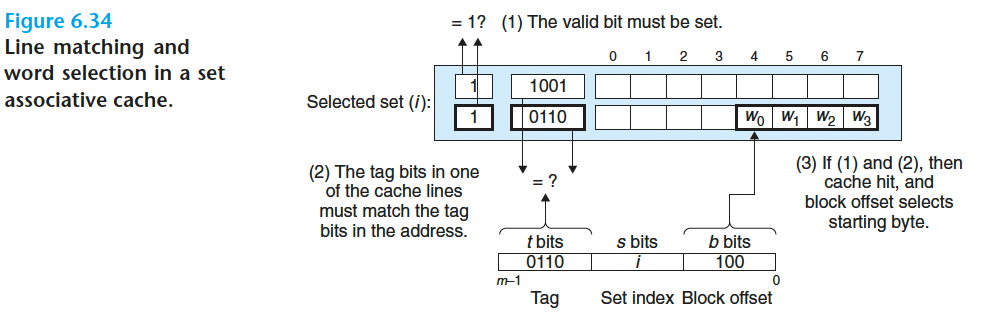
3.不命中时的行替换
如果 CPU 请求的字不在组的任何一行中,那么就是缓存不命中,高速缓存必须从内存中取出包含这个字的块。不过,一旦高速缓存取出了这个块,该替换哪个行呢? 当然, 如果有一个空行,那它就是个很好的候选。但是如果该组中没有空行,那么我们必须从中选择一个非空的行,希望 CPU 不会很快引用这个被替换的行。
6.4.4 全相联高速缓存
只有一个组的缓存结构

Practice Problem 6.12
下面的问题能帮助你加强理解高速缓存是如何工作的。有如下假设:
- 内存是字节寻址的。
- 内存访问的是 1 字节的字(不是 4 字节的字)。
- 地址的宽度为 13 位。
- 高速缓存是 2 路组相联的 (E=2), 块大小为 4 字节 (B=4), 有 8 个组 (S=8) 。
高速缓存的内容如下,所有的数字都是以十六进制来表示的:
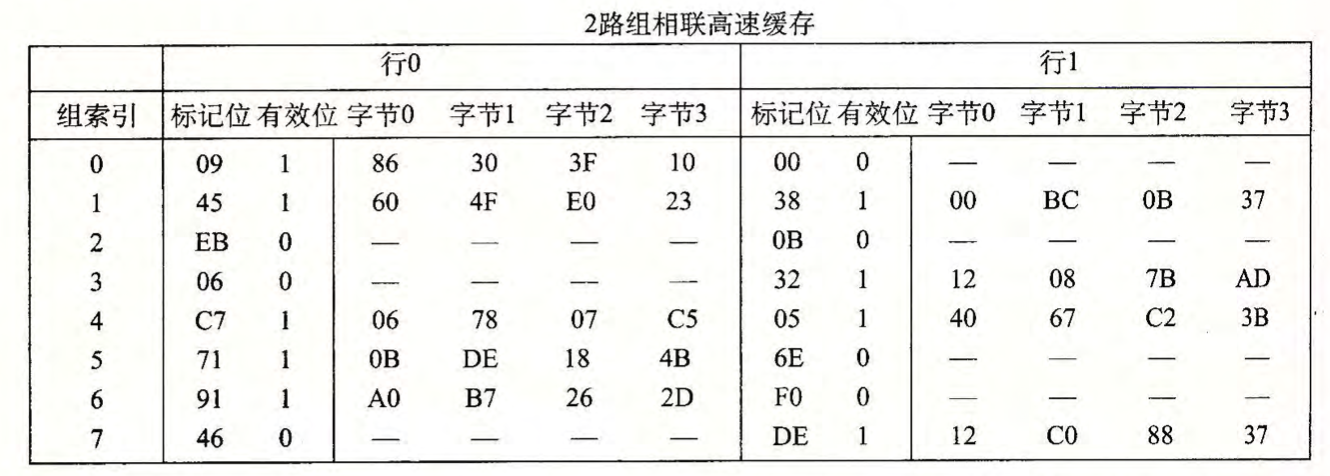
下面的图展示的是地址格式(每个小 方框一个位)。指出(在图中标出)用来确定 下 列内容的字段:
CO 块偏移
CI 组索引
CT 标记位

Practice Problem 6.13
假设一个程序运行在练习题 6-12 中的机器上,它引用地址 0x0E34 处的 1 个字节的字 。指 出访问的高速 缓存条目和 十六进制表示的 返 回的高速 缓存字节值。 指出是否会发生缓存不命中。如果会出现缓存不命中,用“—”来表示“返回的高速 缓存字节”。
A.地址格式

B.内存引用
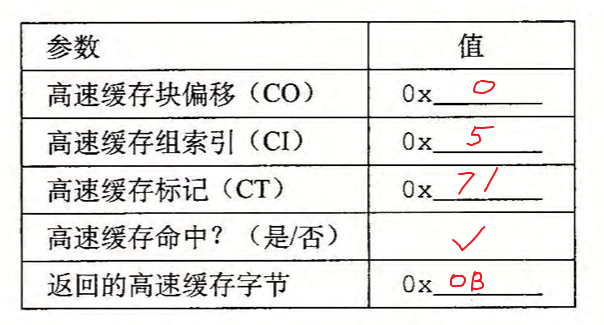
6.4.5 关于写的问题
6.4.6 一个真实的高速缓存层次结构的解剖
只保存指令的高速缓存称为 i-cache
只保存数据的高速缓存称为 d-cache
既保存指令又保存数据的缓存称为 unified cache
6.5 编写对高速缓存友好的代码
编写局部性好的代码能够提高缓存命中率,从而使程序的执行效率更高,速度更快。
这样的代码称为对缓存友好的代码(cache friendly)
下面就是我们用来确保代码高速缓存友好的基本方法:
让最常见的情况运行得快
程序通常把大部分时间都花在少量的核心函数上,而 这些函数通常把大部分时间都花在了少量循环上。所以要把注意力集中在核心函数里的循环上,而忽略其他部分 。
尽量减小每个循环内部的缓存不命中数量
Practice Problem 6.17
在信号处理和科学计算的应用中,转置矩阵的行和列是一个很重要的 问题。从局部性的角度来看,它也很有趣,因为它的引用模式既是以行为主 (row-wise) 的,也是以列为主 (column-wise) 的。例如,考虑下面的转置函数:
1 | typedef int array[2][2]; |
假设在一台具有如下属性的机器上运行这段代码:
- sizeof(int)==4。
- src 数组从地址 0 开始, dst 数组从地址 16(十进制)开始。
- 只有一个 Ll 数据高速缓存,它是直接映射的、直写和写分配的,块大小为 8 个字节。
- 这个高速缓存总的大小为 16 个数据字节,一开始是空的。
- 对 src 和 dst 数组的访问分别是读和写不命中的唯一来源。
A. 对每个 row 和 col, 指明对 src [row] [col] 和 dst [row] [col] 的访问是命中(h) 还是不命中 (m) 。例如,读 src [0] [0]会不命中,写 dst [0] [0] 也不命中。
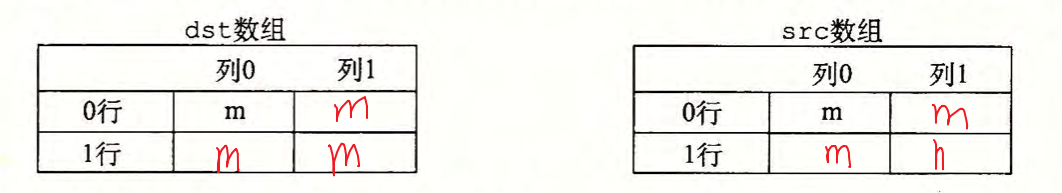
B. 对于一个大小为 32 数据字节的高速缓存重复这个练习。
