
第三章 寄存器(内存访问)
第四章 第一个程序
第三章 寄存器(内存访问)
从访问内存的角度再学习几个寄存器
3.1 ~ 3.5 的笔记内容因为 typora 崩溃全部丢失了 :cry:
检测点 3.1
在 debug 中,用
d 0:0 1f查看内存,结果如下
下面的程序执行前,
AX=0,BX=0,写出每条汇编指令执行完后相关寄存器中的值1
2
3
4
5
6
7
8
9
10
11
12
13
14mov ax,1
mov ds,ax # DS=0001H
mov ax,[0000] # AX=2662H DS=0001H
mov bx,[0001] # BX=E626H DS=0001H
mov ax,bx # AX=E626H DS=0001H
mov ax,[0000] # AX=2662H DS=0001H
mov bx,[0002] # BX=D6E6H DS=0001H
add ax,bx # AX=FD48H DS=0001H
add ax,[0004] # AX=2C14H DS=0001H
mov ax,0 # AX=0000H DS=0001H
mov al,[0002] # AX=00E6H DS=0001H
mov bx,0 # BX=0000H DS=0001H
mov bl,[000C] # BX=0026H DS=0001H
add al,b1 # AX=000CH DS=0001H
内存中的情况如下图所示
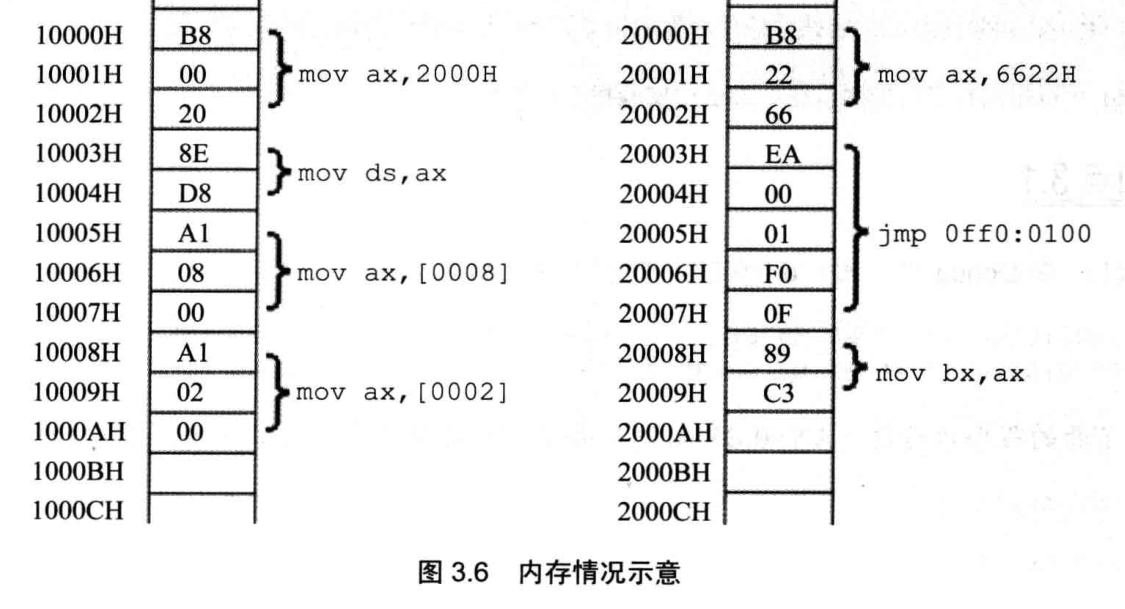
寄存器初始值:CS=2000H,IP=0,DS=1000H,AX=0,BX=0
用汇编指令写出CPU执行的指令序列
写出CPU执行每条指令后,CS、IP和相关寄存器的值
1
2
3
4
5
6mov ax,6622h # ax=6622h bx=0000h cs=2000h ip=0003h ds=1000h
jmp 0ff0:0100 # ax=6622h bx=0000h cs=0ff0h ip=0100h ds=1000h
mov ax,2000h # ax=2000h bx=0000h cs=0ff0h ip=0103h ds=1000h
mov ds,ax # ax=2000h bx=0000h cs=0ff0h ip=0105h ds=2000h
mov ax,[0008] # ax=c389h bx=0000h cs=0ff0h ip=0108h ds=2000h
mov ax,[0002] # ax=ea66h bx=0000h cs=0ff0h ip=010Bh ds=2000h
再次体会:数据和程序有区别吗?如何确定内存中的信息哪些是数据,哪些是程序?
数据和程序在内存中的形式都是二进制数,没有什么不同。CPU将 CS:IP 指向的二进制数当作指令,DS:[···] 指定的地址当作数据
3.6 栈
栈的进出顺序:LIFO (Last In First Out)
3.7 CPU 提供的 栈机制
基于 8086CPU 编程的时候,可以将一段内存当作栈来使用
8086CPU提供入栈和出栈指令,其中最基本的两个是 PUSH 和 POP
8086CPU的入栈和出栈操作都是以字为单位进行的
如何指定一段内存,并把它用作栈呢?CPU又如何知道栈顶的位置呢?
先回答第二个问题,8086CPU有SS 和 SP寄存器,SS:SP 指定栈顶的地址
书中这里并没有交代如何指定一段内存用作栈 :cry:
3.8 栈顶越界问题
这个问题在两个情形下会产生:栈已经满了继续入栈;栈已经空了继续出栈。
我们可以提供两个地址分别标记栈的边界,在每次入栈和出栈的时候增加一个检测环节,就能够避免栈顶越界带来的问题。
遗憾的是,8086CPU并没有提供相应的寄存器。也就是说,8086CPU只知道栈顶地址,不知道栈的边界
3.9 push、pop 指令
1 | push 寄存器 ;将一个寄存器中的数据入栈 |
问题3.8
编程:
- 将 10000H~1000FH 这段空间当作栈,初始状态栈是空的;
- 设置 AX=001AH ,BX=001BH ;
- 将 AX 、BX中的数据入栈;
- 将 AX 、BX清零;
- 从栈中恢复AX 、BX原来的内容
1 | mov ax,1000 |
问题3.9
编程:
- 将10000H~1000FH 这段空间当作栈,初始状态栈是空的;
- 设置 AX=001AH , BX=001BH ;
- 利用栈交换 AX 和 BX 的内容。
1 | mov ax,1000 |
检测点 3.2
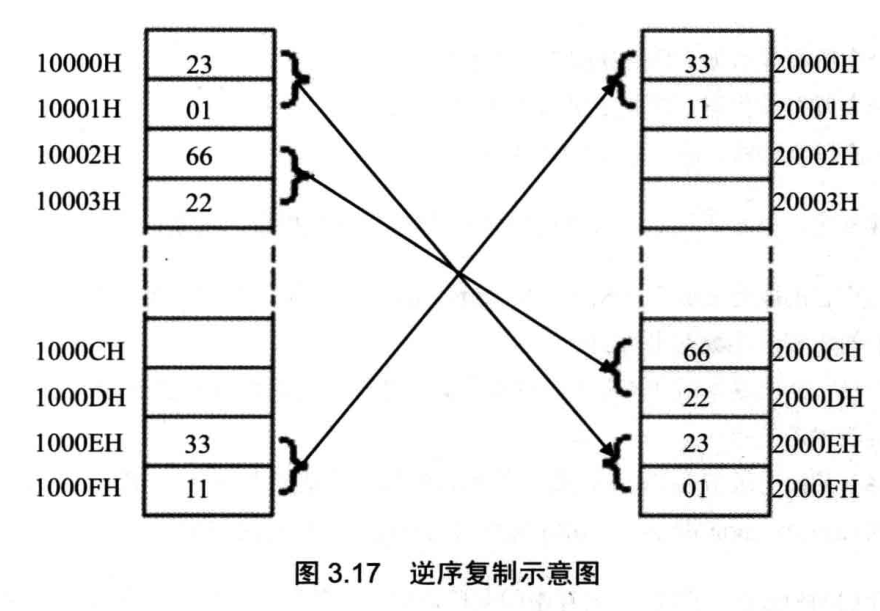
补全下面的程序,使其可以将10000H~1000FH 中的8个字,逆序复制到 20000H~2000FH 中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15mov ax,1000H
mov ds,ax
mov ax,2000
mov ss,ax
mov sp,0010
push [0]
push [2]
push [4]
push [6]
push [8]
push [A]
push [C]
push [E]
补全下面的程序,使其可以将10000H~1000FH中的8个字,逆序复制到20000H~2000FH中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15mov ax,2000H
mov ds,ax
mov ax,1000H
mov ss,ax
mov sp,0
pop [E]
pop [C]
pop [A]
pop [8]
pop [6]
pop [4]
pop [2]
pop [0]
实验二 用机器指令和汇编指令编程
实验任务
使用Debug,将下面的程序段写入内存,逐条执行,根据指令执行后的实际运行情况填空。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15mov ax,ffff
mov ds,ax
mov ax,2200
mov ss,ax
mov sp,0100
mov ax,[0] ;ax=C0EAH
add ax,[2] ;ax=C0FCH
mov bx,[4] ;bx=30F0H
add bx,[6] ;bx=6021H
push ax ;sp=00FEH;修改的内存单元的地址是2200:FE 内容为 C0FCH
push bx ;sp=00FCH;修改的内存单元的地址是2200:FC 内容为 6021H
pop ax ;sp=00FEH;ax=6021H
pop bx ;sp=0100H;bx=C0FCH
push[4] ;sp=00FEH;修改的内存单元的地址是2200:FE 内容为 30F0H
push[6] ;sp=00FCH;修改的内存单元的地址是2200:FC 内容为 2F31H将上述指令写入内存,并设置CS:IP
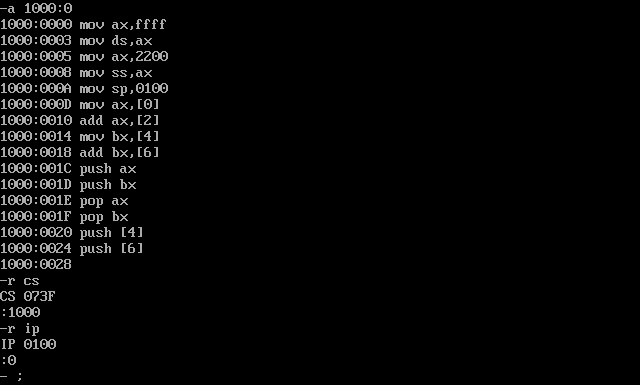
开始运行程序
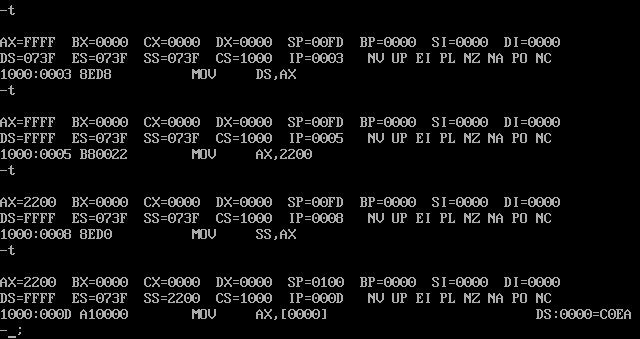
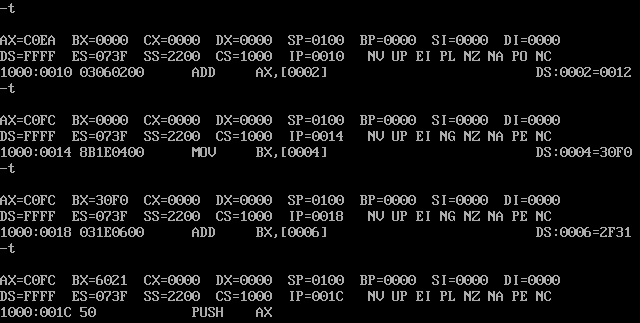
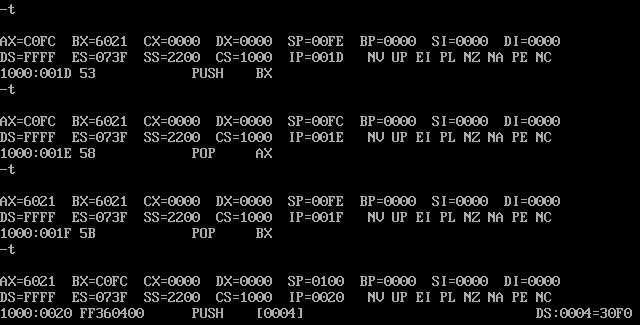
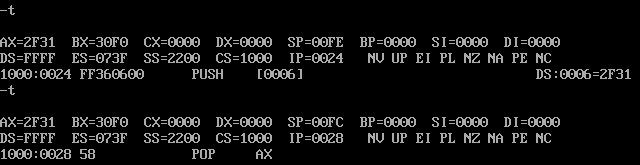
仔细观察下图中的实验过程,然后分析:为什么2000:0-2000:f中的内容会发生改变?
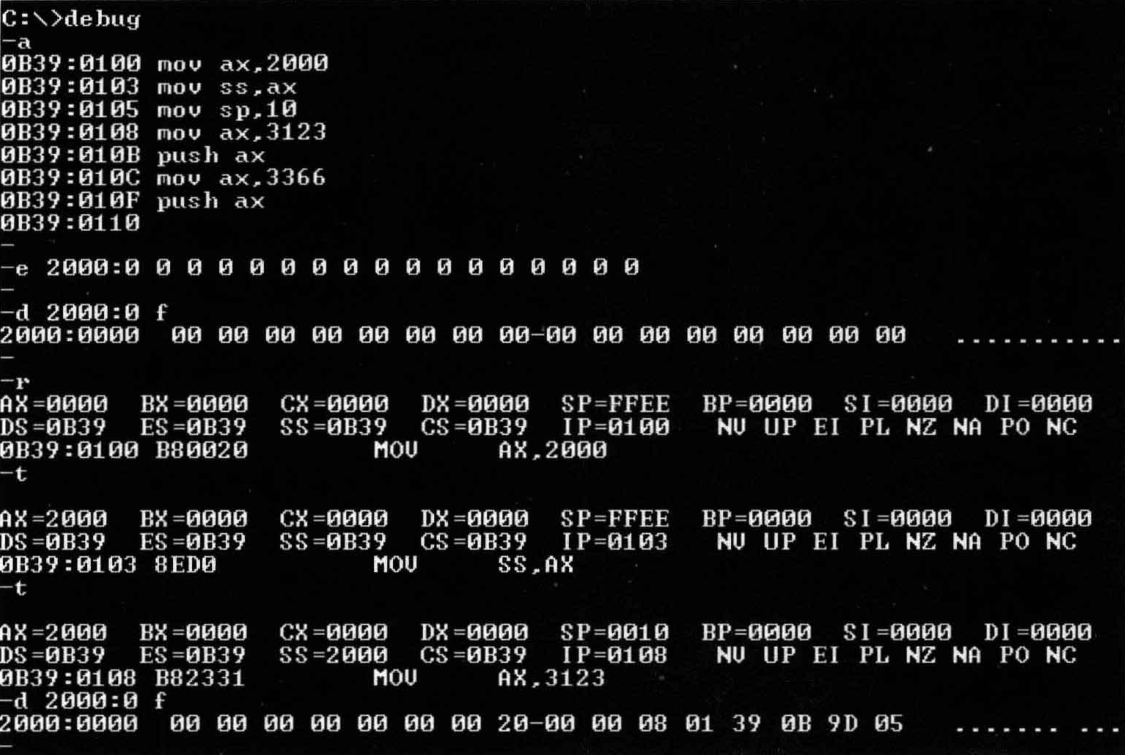
猜测:1.前面已经讲过,在执行
mov ss,ax之后,mov sp,10会被自动执行,所以我猜测是在自动执行mov sp,10时使用了栈的内存2.设置栈顶后,原本存储的值被简单丢弃了
查到的解答:t命令实际是引发了单步中断,执行中断例程时,CPU会将一些中断例程使用的的寄存器变量自动压栈到栈中,此例中就包括了上述的寄存器变量的值。所以第一个猜测基本正确了
第四章 第一个程序
4.1 一个源程序从写出到执行的过程
编写程序,得到文本文件
编译,得到目标文件;连接,得到可执行文件
可执行文件通常包含两个部分:数据和程序;描述信息(程序有多大、要占用多少内存空间)
执行
4.2 源程序
1 | assume cs:codesg |
这个源程序中有汇编指令(有对应的机器码)和伪指令(没有对应的机器码,编译器负责识别和执行)
伪指令
XXX segment
XXX ends
segment和ends是成对使用而且必须使用的伪指令,用来说明一个段的开始和结束,具体格式:1
2
3段名 segment
···
段名 ends一个汇编程序可以由多个段组成,这些段用来存放代码、数据或当作栈来使用
end
用来标记程序的结束,编译器看到这个指令就会停止编译
assume
从名字可以看出,这条语句用来做一个假设。
它假设 某一个段寄存器和程序中的某一个用 segment···ends 定义的段 相关联
源程序中的 “程序”
通过1我们知道,源程序中既有汇编指令又有伪指令,其中只有汇编指令最终会被翻译成机器语言并执行,我们称这部分指令和数据为 程序
所以以后记得,源程序 和 程序 是有区别的
标号
本节开头给出的源程序中的
codesg就是一个标号。它最终会被编译和连接软件处理为一个段的段地址程序的结构
源程序是由一些段构成的。我们可以在这些段中存放代码、数据、或将某个段当作栈空间
程序返回
一个程序结束后,将CPU 的 控制权 交还给使得它得以运行的程序,这个过程称为 程序返回 (注意返回的是控制权)
那么如果返回? 需要在程序的末尾添加返回的程序段
1
2mov ax,4c00H
int 21H本节开头源程序中的这两行指令的功能就是程序返回
4.3 编辑源程序
使用顺手的文本编辑器编辑,并把源程序保存为 xxx.asm 即可
4.4 编译
.asm 文件编译完成后是 .obj 格式的
用的编译器是微软的 masm ,尝试了一下,编译成功了。但是生成的 .obj 文件全都在 masm.exe 所在的文件夹,那个文件夹里有好多文件,每次都要一个一个找,好麻烦:sweat_smile: ,以后找个办法指定 OBJ 文件和 ASM 文件在同一个文件夹
4.5 连接
.obj 文件连接完成后是 .exe 格式的可执行文件
用的连接器是微软的 overlay linker,文件名 link.exe
连接的作用有以下几个:
- 当源程序很大时,可以将它分为多个源程序文件来编译,每个源程序编译成为目标文件后,再用连接程序将它们连接到一起,生成一个可执行文件;
- 程序中调用了某个库文件中的子程序,需要将这个库文件和该程序生成的目标文件连接到一起,生成一个可执行文件;
- 一个源程序编译后,得到了存有机器码的目标文件,目标文件中的有些内容还不能直接用来生成可执行文件,连接程序将这些内容处理为最终的可执行信息。所以,在只有一个源程序文件,而又不需要调用某个库中的子程序的情况下,也必须用连接程序对目标文件进行处理,生成可执行文件。
4.6 以简化的方式进行编译和连接
1 | masm c:\first; 编译,并忽略中间文件 |
4.7 first.exe 的执行
4.8 谁将可执行文件中的程序装载进入内存并使它运行?
是 DOS 系统的 SHELL —— command
4.9 程序执行过程的跟踪
跟踪过程就是调试过程,用 debug
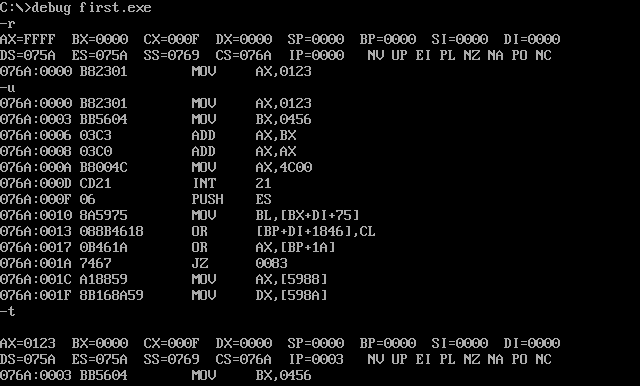
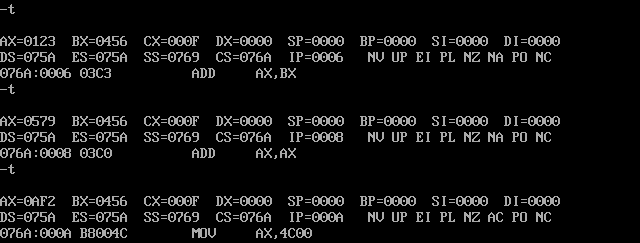
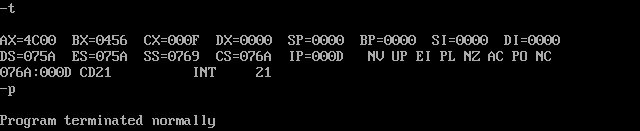
注意,最后的 int 21 指令要用 p 命令执行
实验三 编程、编译、连接、跟踪
将下面的程序保存为 t1.asm 文件,将其生成为可执行文件 t1.exe
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18assume cs:codesg
codesg segment
mov ax,2000H
mov ss,ax
mov sp,0
add sp,10
pop ax
pop bx
push ax
push bx
pop ax
pop bx
mov ax,4c00H
int 21H
codesg ends
end开始实验:
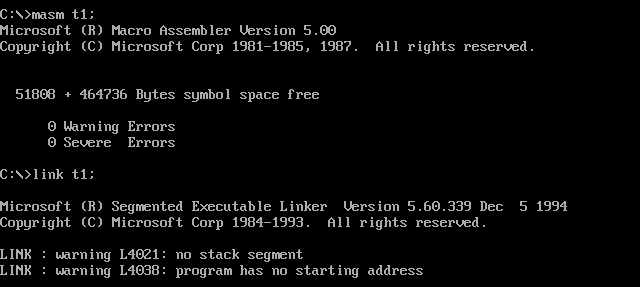
用Debug跟踪 t1.exe 的执行过程,写出每一步执行后,相关寄存器中的内容和栈顶的内容。
开始调试:
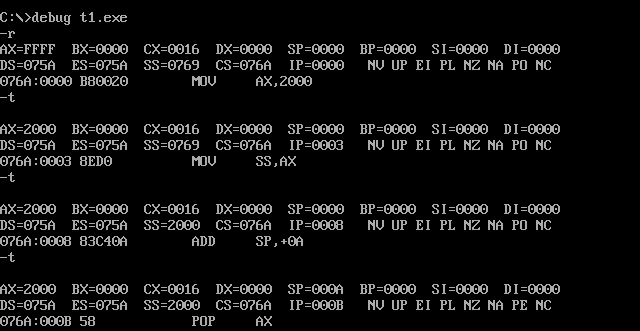
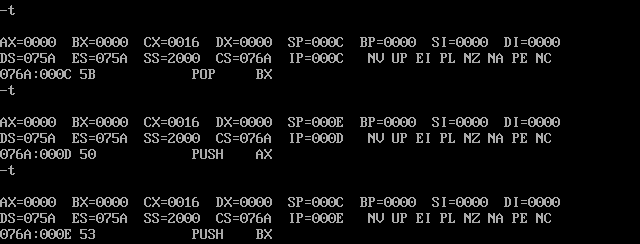
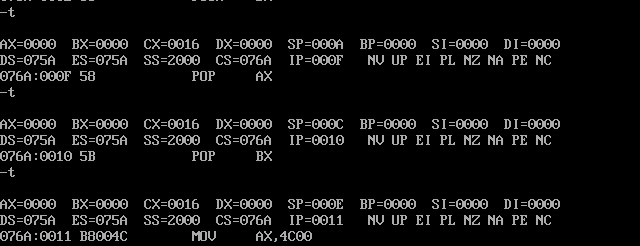
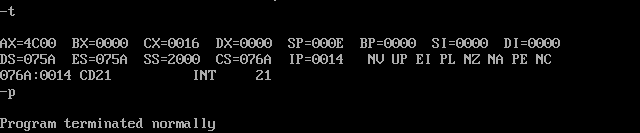
PSP的头两个字节是 CD20 ,用 debug 加载 t1.exe ,查看PSP的内容
加载后,PSP头字节在 CS:IP 之前256字节的地方
