

第一章 了解SQL
1.1 数据库基础
1.1.1 什么是数据库database
数据库是保存有组织的数据的容器。
1.1.2 表table
表用来存储结构化的数据。
1.1.3 列column和数据类型datatype
表由列组成,列存储着表中某部分信息。
列,表中的一个字段。
数据类型,能够存储的数据的类型。如数字、文本、金额等
1.1.4 行row
行,表中的一个记录
1.1.5 主键primary key
主键,可以唯一标识行的某列或某些列
1.2 什么是SQL(Structured Query Language)
SQL,结构化查询语言,是一种专门用来与数据库通信的语言
第二章 MySQL简介
2.1 什么是MySQL
MySQL是一种数据库管理系统,它能够对数据库中的数据进行存储、检索、管理和处理。
2.1.1 客户机-服务器软件
MySQL是一个客户机-服务器DBMS(database manage system)
2.1.2 MySQL版本
2.2 MySQL工具
2.2.1 MySQL命令行实用程序
第三章 使用MySQL
3.1 连接
3.2 选择数据库
3.3 了解数据库和表
| 语句 | 用途 |
|---|---|
| SHOW DATABASES; | 显示可用的数据库 |
| SHOW TABLES; | 显示当前数据库中的表 |
| SHOW COLUMNS FROM accounts或者DESCRIBE accounts | 显示accounts表中的字段 |
使用HELP SHOW 查看所有可用的SHOW语句
第四章 检索数据
4.1 SELECT 语句
4.2 检索单个列
SELECT USER FROM accounts; 从accounts表中检索USER 字段
4.3 检索多个列
4.4 检索所有列
SELECT * FROM accounts; 检索accounts表中的所有列
4.5 检索不同的行
SELECT DISTINCT USER FROM accounts; 只显示USER字段中不重复的值
4.6 限制结果
SELECT USER FROM accounts LIMIT 1,2;
从accounts表中检索USER 字段且只显示第二行及第三行
SELECT USER FROM accounts LIMIT 1,5;
从accounts表中检索USER 字段且只显示从第二行开始的5行
4.7 使用完全限定的表名
第五章 排序检索数据
5.1 排序数据
SELECT VARIABLE_NAME FROM variables_info ORDER BY VARIABLE_NAME;
检索VARIABLE_NAME字段并按其字母顺序排序
5.2 按多个列排序
5.3 指定排序方向
SELECT VARIABLE_NAME FROM variables_info ORDER BY VARIABLE_NAME DESC;
检索VARIABLE_NAME字段并按其字母顺序降序排序
DESC关键字只应用到直接位于其前面的列名
第六章 过滤数据
6.1 使用WHERE 子句
SELECT VARIABLE_NAME FROM variables_info WHERE VARIABLE_NAME=’var’;
检索VARIABLE_NAME里值为var的行
WHERE 和ORDER BY 同时使用时,ORDER BY 要放在WHERE 之后
6.2 WHERE子句操作符

6.2.1 检查单个值

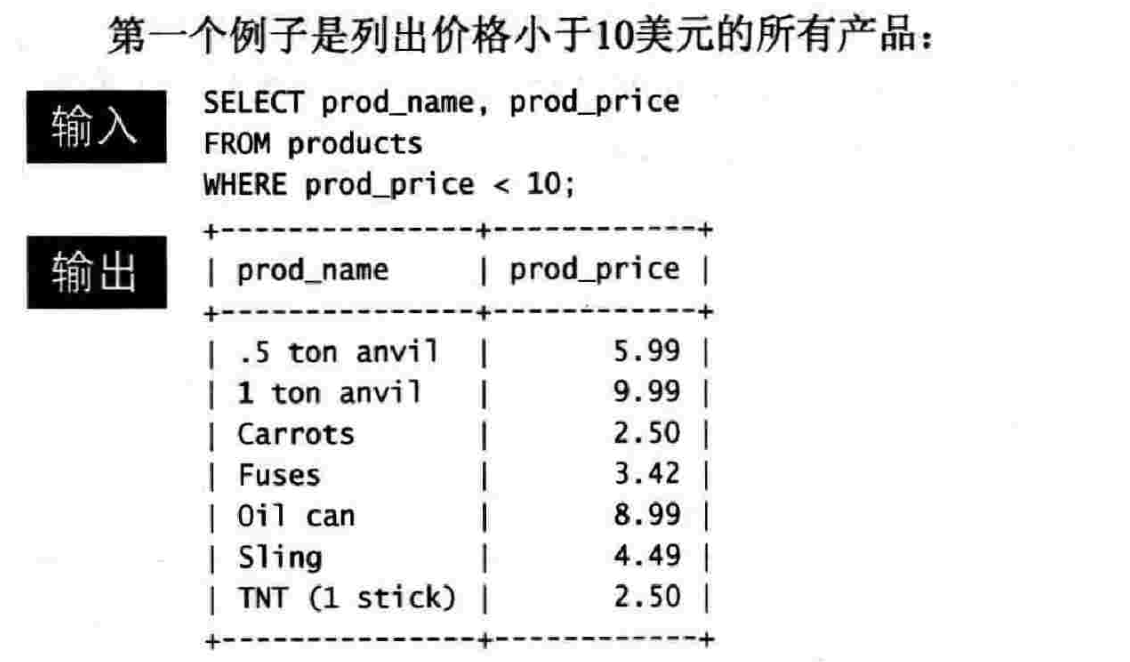
6.2.2 不匹配检查


6.2.3 范围值检查

6.2.4 空值检查

NULL :无值,它与字段包含0、空字符串或仅仅包含空格不同
第七章 高级数据过滤
7.1 组合WHERE子句
7.1.1 AND操作符

7.1.2 OR操作符

7.1.3 计算次序
AND 优先级比 OR 高

7.2 IN 操作符
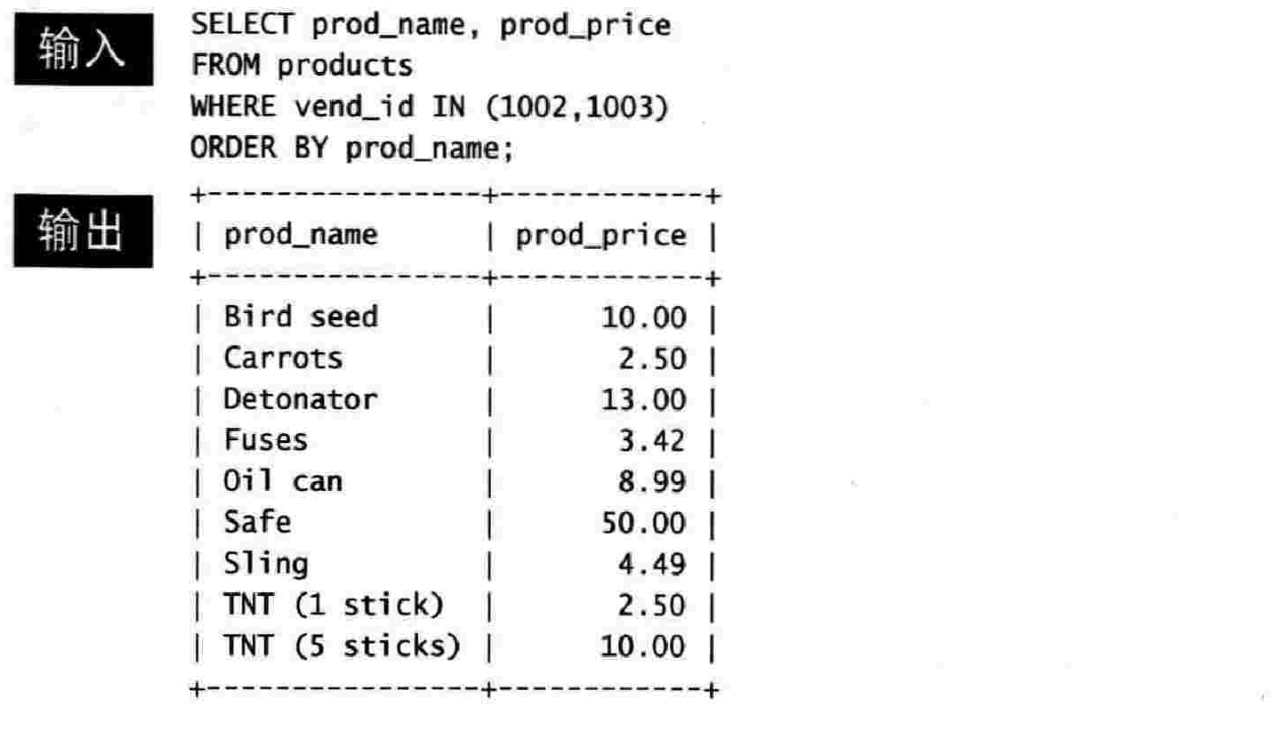

7.3 NOT 操作符
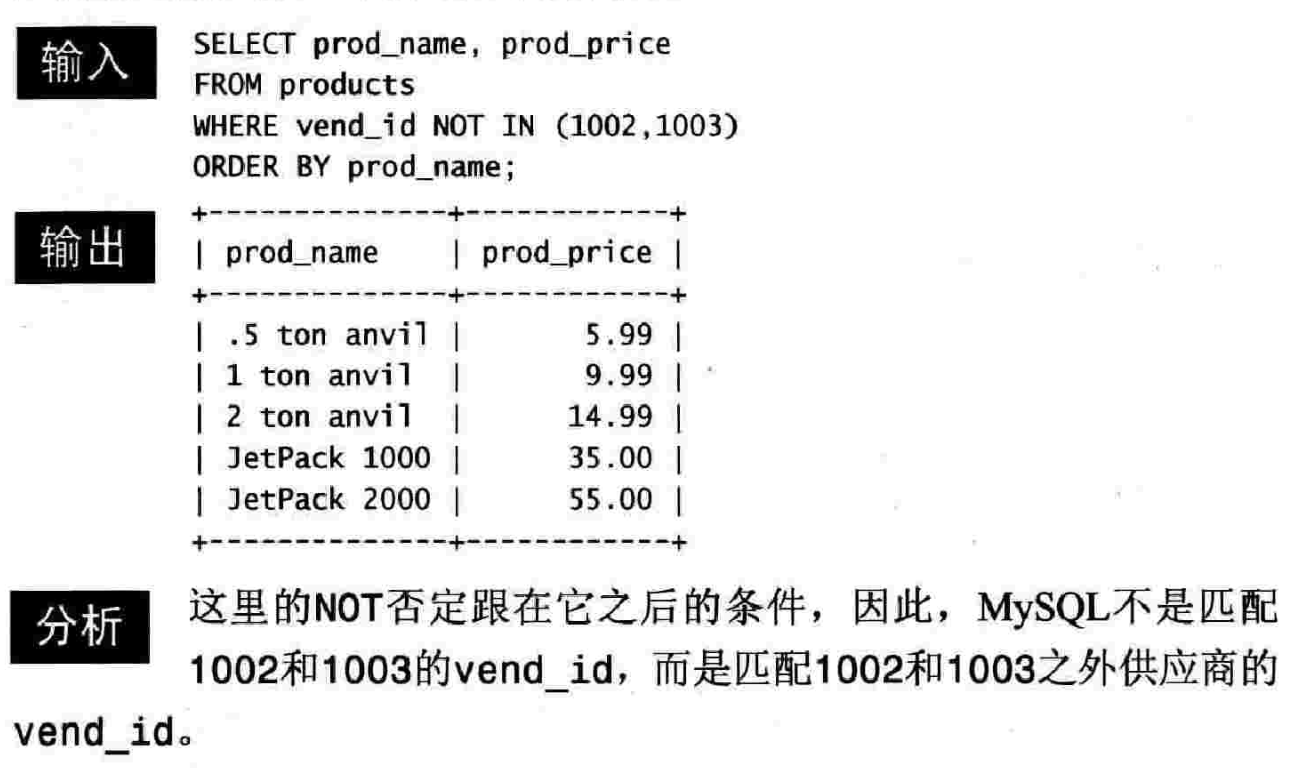
第八章 使用通配符进行过滤
8.1 LIKE 操作符
通配符(wildcard):用来匹配值的一部分的特殊字符
8.1.1 %通配符

% 表示任意字符出现任意次数
8.1.2 _ 通配符
_ 匹配单个字符
8.2 使用通配符的技巧
细心使用,不要滥用
第九章 使用正则表达式(regular expression)进行搜索
9.1 正则表达式介绍
9.2 使用MySQL正则表达式
9.2.1 基本字符匹配


正则表达式中 ‘.’ 匹配任意一个字符
9.2.2 进行OR匹配

9.2.3 匹配几个字符之一

9.2.4 匹配范围
[1-9] 匹配1,2,3,4,5,6,7,8,9
[2-5] 匹配2,3,4,5

9.2.5 匹配特殊字符
匹配特殊字符时需要转义
9.2.6 匹配字符类

9.2.7 匹配多个实例



匹配连在一起的4位数字
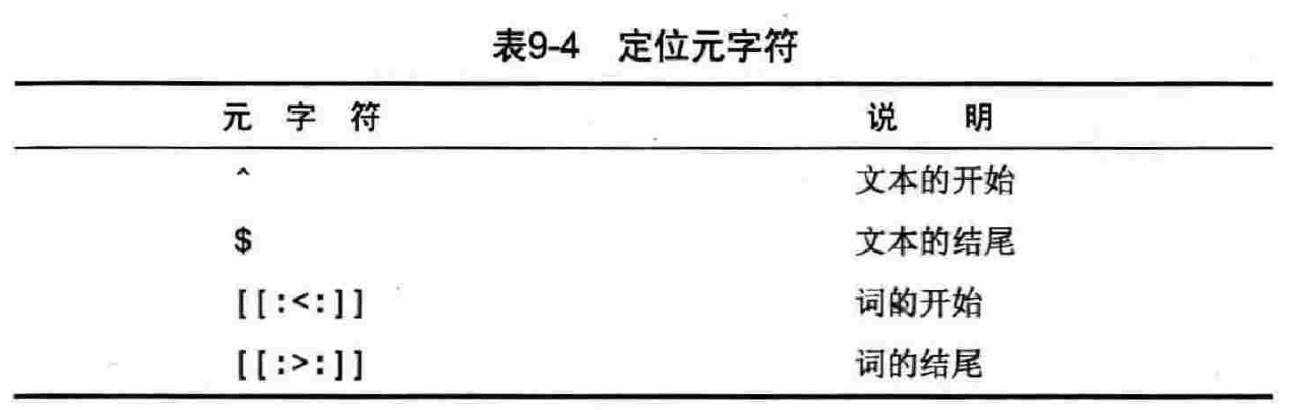
9.2.8 定位符


第十章 创建计算字段
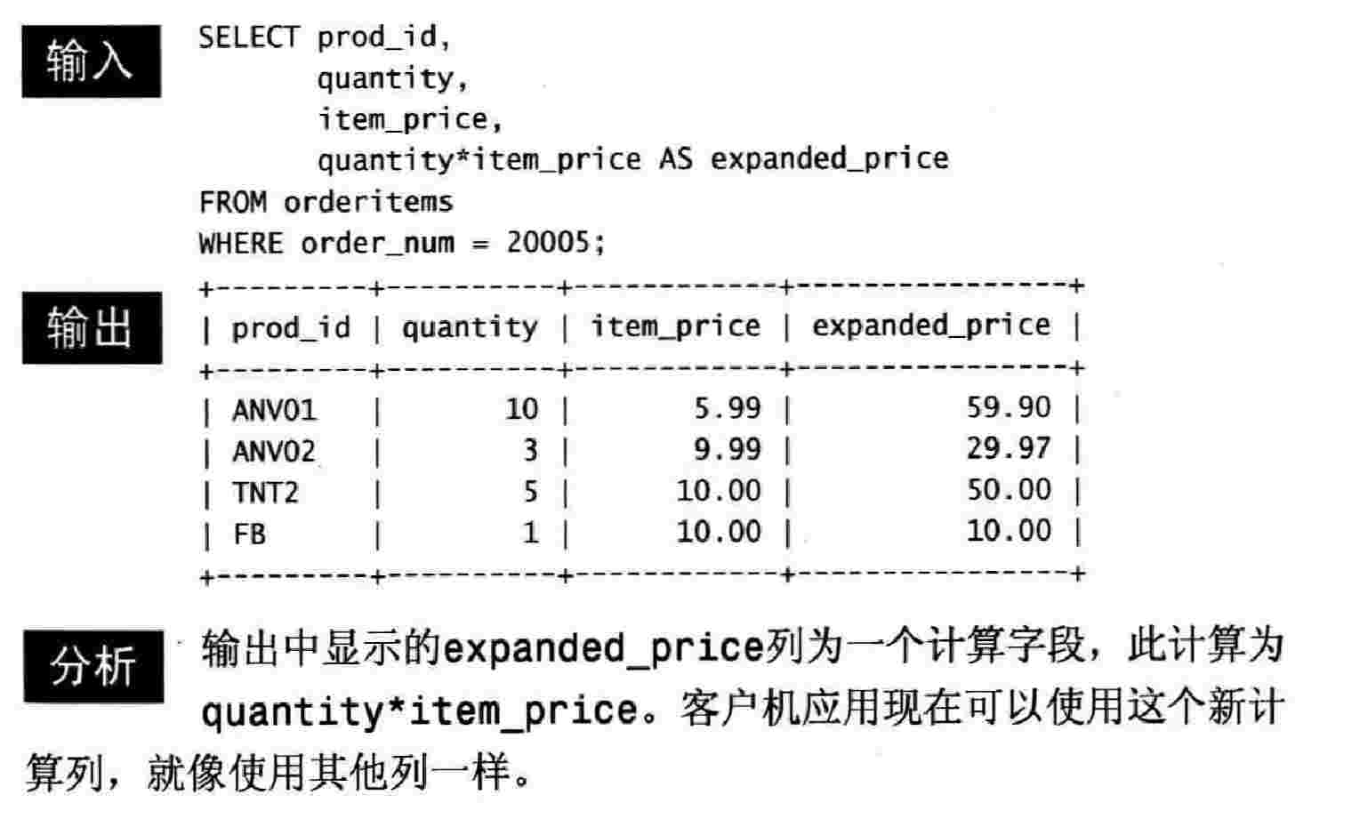
10.1 计算字段
计算字段用来对表中的数据进行计算或者其他处理,它本身并不实际存在于数据库表中,而是运行时在SELECT语句内创建的。
10.2 拼接字段
拼接 concatenate

RTrim() 删去串右边的空格
LTrim() 删去串左边的空格

使用别名

别名主要是为了客户机引用,相当于提供了一个变量名
10.3 执行算术计算
第十一章 使用数据处理函数
11.1 函数
11.2 使用函数
11.2.1 文本处理函数



11.2.2 日期和时间处理函数
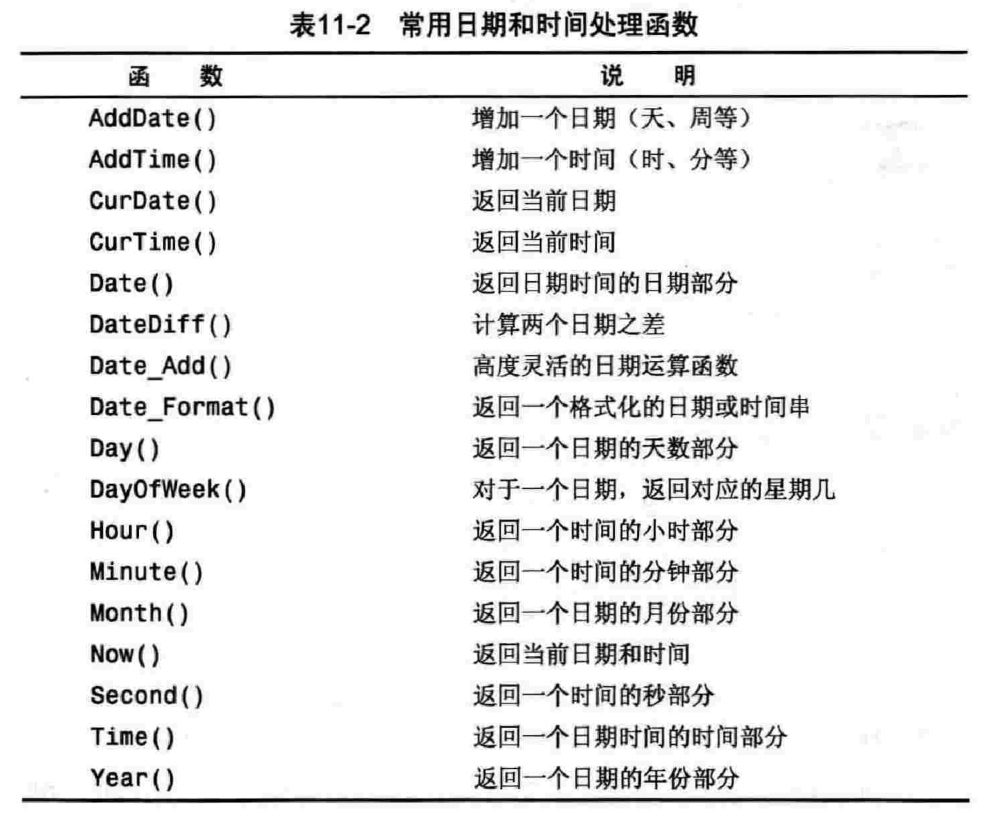

11.2.3 数值处理函数

第十二章 汇总数据
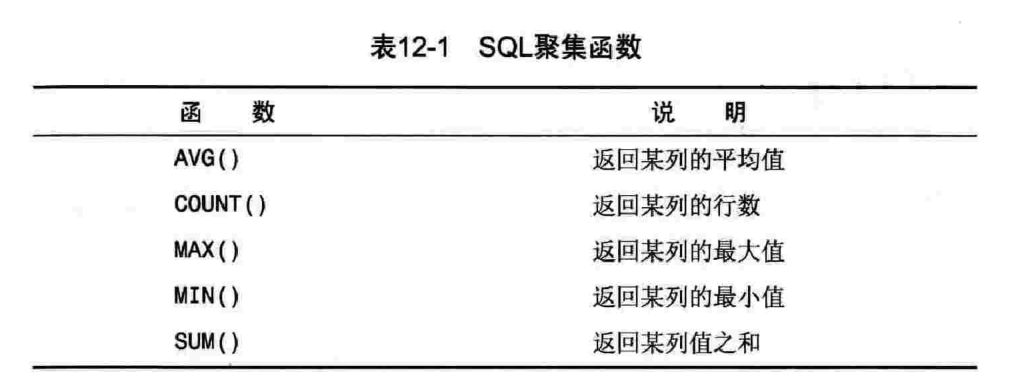
12.1 聚集函数
聚集函数(aggregate function) 运行在行组上,计算和返回单个值的函数
12.1.1 AVG()函数



12.1.2 COUNT()函数
COUNT()函数负责计数,可以利用其确定表中行的数目或符合特定条件的行的数目
COUNT(*)对表中所有行进行统计,不管表列中包含的是空值(NULL)还是非空值。
COUNT(column)对指定的列进行统计,不统计NULL值
12.1.3 MAX()函数
要求指定列名,返回指定列中的最大值,忽略NULL值

12.1.4 MIN()函数
除了返回最小值,其它要求和特性与MAX()函数相同
12.1.5 SUM()函数
要求指定列名
12.2 聚集不同值

12.3 组合聚集函数


第十三章 分组数据
13.1 数据分组
13.2 创建分组

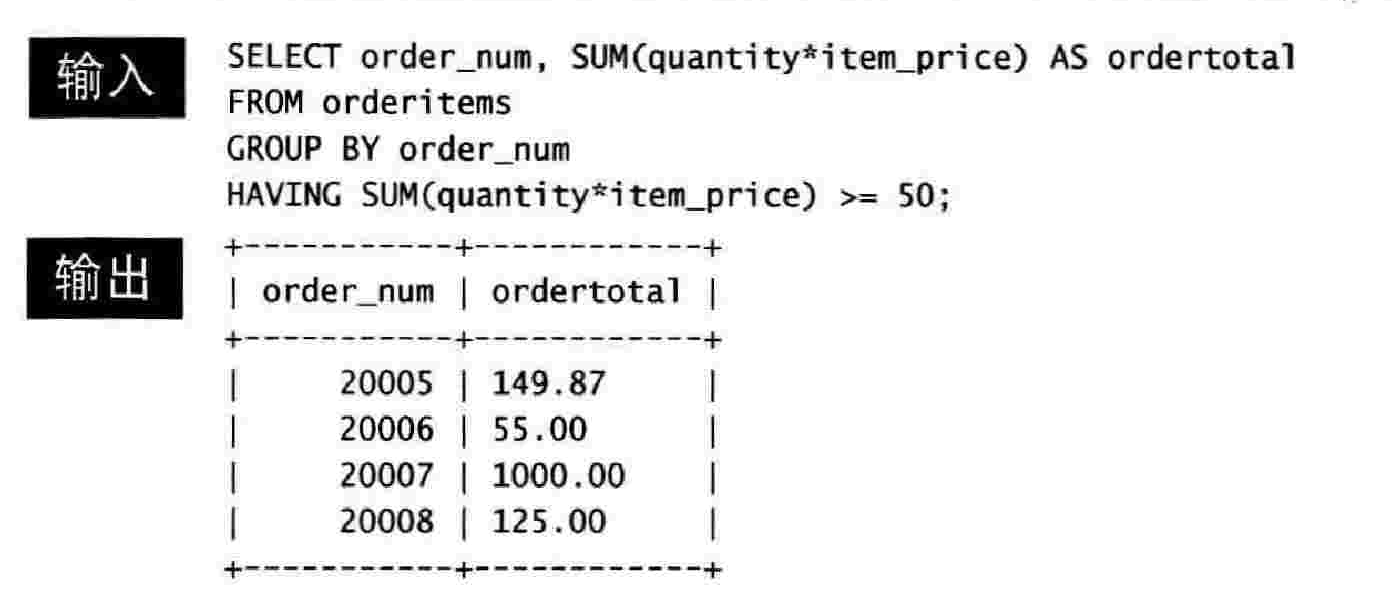
13.3 过滤分组
使用 HAVING 关键字过滤分组
之前学的 WHERE 关键字是用来过滤行的


13.4 分组和排序


13.5 SELECT子句顺序


第十四章 使用子查询
14.1 子查询
SQL允许创建子查询(subquery),即嵌套在其他查询中的查询。
14.2 利用子查询进行过滤


14.3 作为计算字段使用子查询
第十五章 联结表
15.1 联结
15.1.1 关系表
外键(foreign key) :某个表中的一列,它包含另一个表的主键值,定义了两个表之间的关系。
15.1.2 为什么要使用联结
联结就是为了在多个关系表之间进行查询
15.2 创建联结
mysql> SELECT vend_name,prod_name,prod_price
-> FROM vendors,products
-> WHERE vendors.vend_id=products.vend_id
-> ORDER by vend_name,prod_name;
15.2.1 WHERE子句的重要性

15.2.2 内部联结
mysql> SELECT vend_name,prod_name,prod_price
-> FROM products INNER JOIN vendors
-> ON products.vend_id=vendors.vend_id
-> ;
15.2.3 联结多个表
SQL对一条SELECT语句中能够联结的表的数目没有限制。
mysql> SELECT prod_name,vend_name,prod_price,quantity
-> FROM products,vendors,orderitems
-> WHERE products.vend_id=vendors.vend_id
-> AND orderitems.prod_id=products.prod_id
-> AND order_num=20005;
mysql> SELECT cust_name,cust_contact
-> FROM customers,orders,orderitems
-> WHERE orders.order_num=orderitems.order_num
-> AND customers.cust_id=orders.cust_id
-> AND prod_id=’TNT2’;
第十六章 创建高级联结
16.1 使用表别名
表的别名只在查询执行中使用,不返回到客户机
16.2 使用不同类型的联结
16.2.1 自联结
mysql> SELECT p1.prod_name,p1.prod_id
-> FROM products AS p1,products AS p2
-> WHERE p1.vend_id=p2.vend_id
-> AND p2.prod_id=’DTNTR’;
16.2.2 自然联结

16.2.3 外部联结

16.3 使用带聚集函数的联结
mysql> SELECT cust_name,orders.cust_id,COUNT(orders.order_num) AS num_ord
-> FROM customers,orders
-> WHERE customers.cust_id=orders.cust_id
-> GROUP BY orders.cust_id;
+————————+————-+————-+
| cust_name | cust_id | num_ord |
+————————+————-+————-+
| Coyote Inc. | 10001 | 2 |
| Wascals | 10003 | 1 |
| Yosemite Place | 10004 | 1 |
| E Fudd | 10005 | 1 |
+————————+————-+————-+
4 rows in set (0.00 sec)
16.4 使用联结和联结条件

第十七章 组合查询
17.1 组合查询

17.2 创建组合查询
UNION
17.2.1 使用UNION
mysql> SELECT prod_name
-> FROM products
-> WHERE prod_price<=5
-> UNION
-> SELECT prod_name
-> FROM products
-> WHERE vend_id IN (1001,1002);
+———————-+
| prod_name |
+———————-+
| Carrots |
| Fuses |
| Sling |
| TNT (1 stick) |
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
| Oil can |
+———————-+
8 rows in set (0.00 sec)
17.2.2 UNION规则

17.2.3 包含或取消重复的行
UNION 语句默认会删除重复的行,如果不想删除重复行,可以使用 UNION ALL
17.2.4 对组合查询结果排序
UNION联结的SELECT 语句只允许使用一条 ORDER BY语句,放在最后
第十八章 全文本搜索
18.2 使用全文本搜索
18.2.1 启用全文本搜索支持

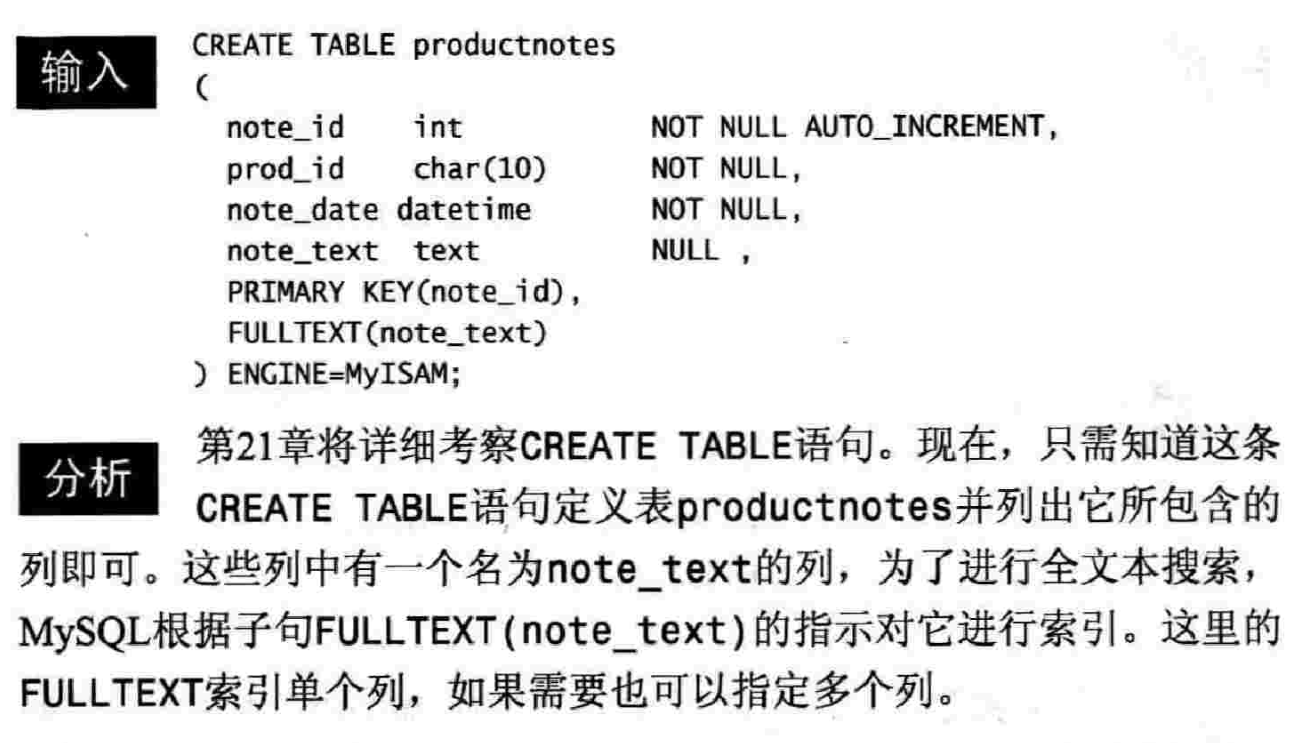
18.2.2 进行全文本搜索
18.2.3 使用查询扩展

18.2.4 布尔文本搜索
使用布尔文本搜索时要提供

布尔操作非常缓慢



18.2.5 全文本搜索说明


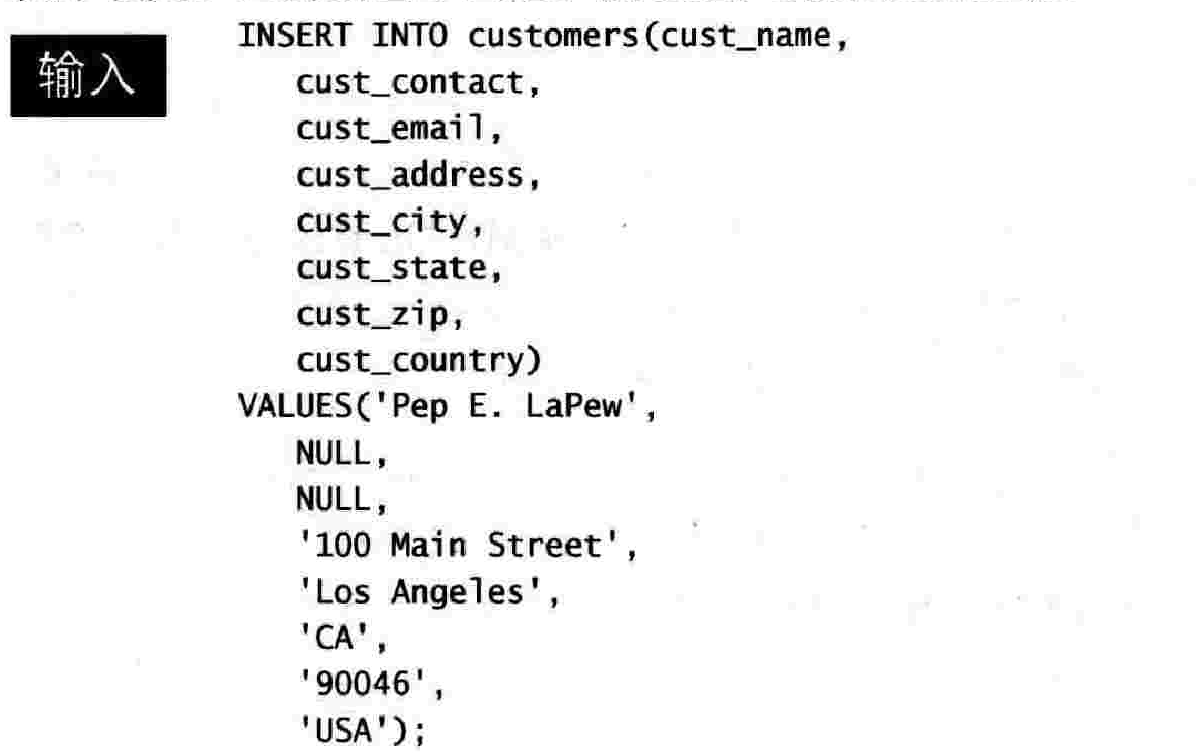
第十九章 插入数据
19.1 数据插入
INSERT

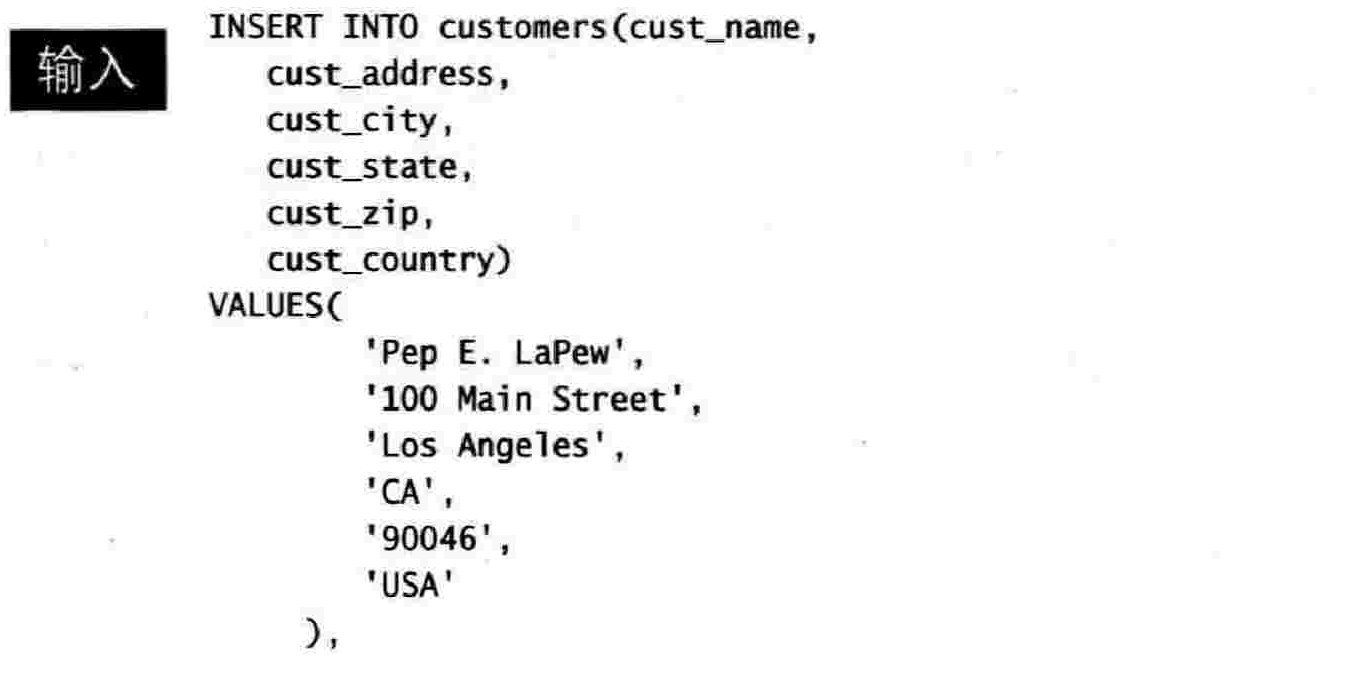
19.2 插入完整的行
19.3 插入多个行

19.4 插入检索出的数据

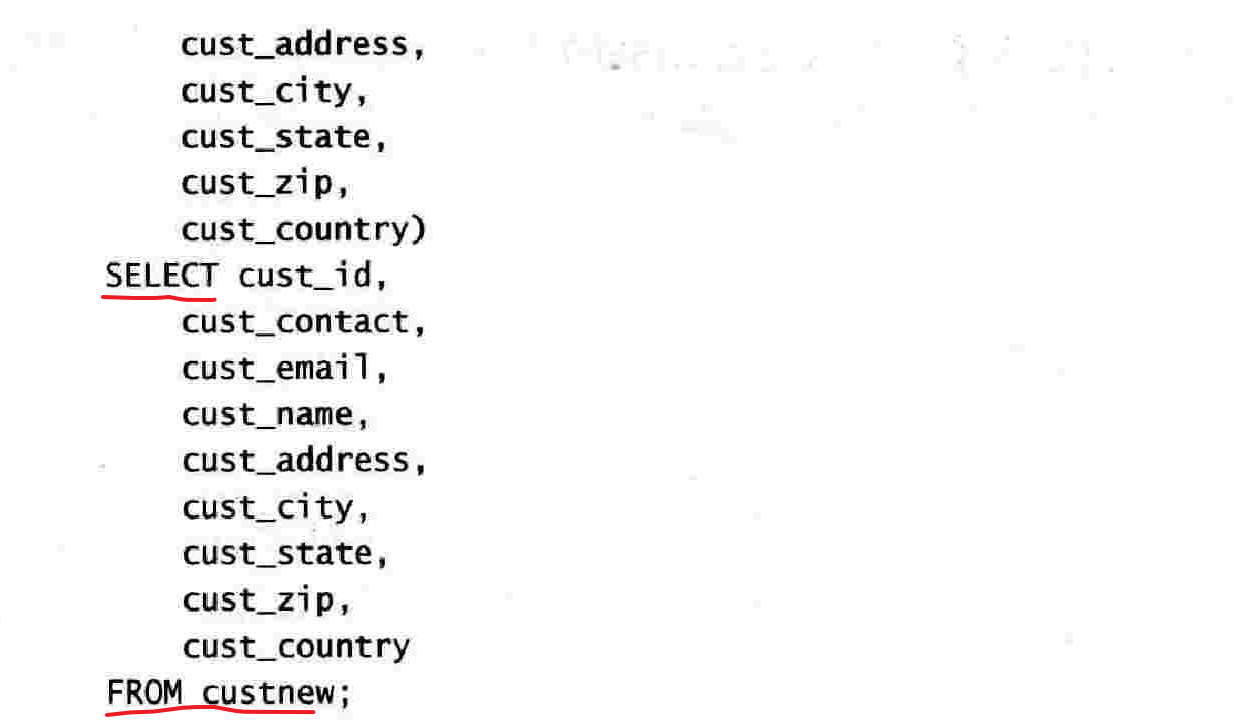
第二十章 更新和删除数据
20.1 更新数据
UPDATE

20.2 删除数据
20.3 更新和删除的指导原则

第二十一章 创建和操纵表
21.1 创建表
21.1.1 创建表之前需要知道的事情

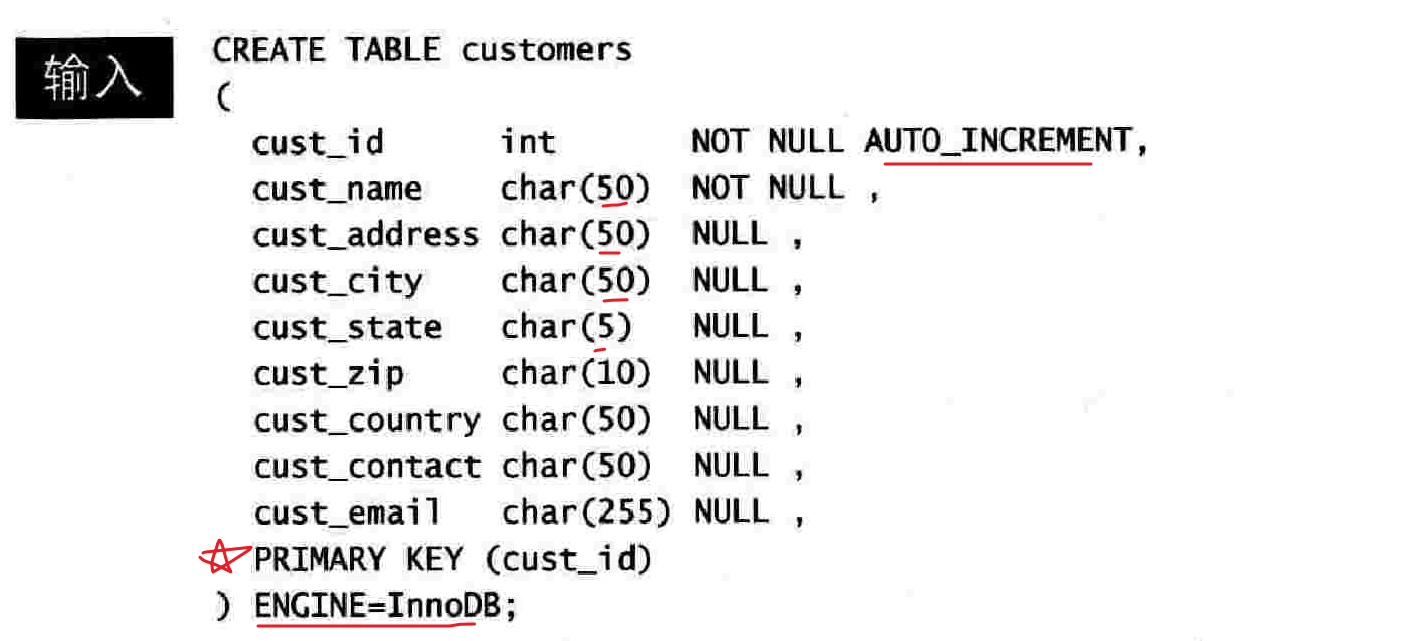
21.1.2 使用NULL值
21.1.4 使用AUTO_INCREMENT
21.1.5 指定默认值


21.2 更新表
ALTER TABLE

21.3 删除表

21.4 重命名表
RENAME TO

第二十二章 使用视图
22.1 视图
视图不是表
22.1.1 为什么使用视图

视图仅仅是用来查看存储在别处的数据的一种措施
22.1.2 视图的规则和限制
视图命名必须唯一
视图可以和表一起使用。视图可以和表联结。
22.2 使用视图

22.2.1 利用视图简化复杂的联结
22.2.5 更新视图
注意,并非所有视图都可以更新(进行INSERT,UPDATE,DELETE等操作)
第二十三章 使用存储过程
23.1 存储过程

类似于shell脚本
23.2 为什么需要存储过程
简单、安全、高性能
23.3 使用存储过程
23.3.1 执行存储过程
CALL
23.3.2 创建存储过程

mysql> CREATE PROCEDURE productpricing()
-> BEGIN
-> SELECT Avg(prod_price) AS priceaverage
-> FROM products;
-> END //
Query OK, 0 rows affected (0.03 sec)
mysql> CALL productpricing()
-> //
+———————+
| priceaverage |
+———————+
| 16.133571 |
+———————+
1 row in set (0.00 sec)
Query OK, 0 rows affected (0.01 sec)
23.3.3 删除存储过程

23.3.4 使用参数


23.3.6 检查存储过程

第二十四章 使用游标
24.1 游标
游标是用来在查询结果集中进行数据选择的工具
24.2 使用游标
24.2.1 创建游标

24.2.2 打开和关闭游标

24.2.3 使用游标数据
FETCH

一个综合存储过程、游标、逐行处理以及存储过程调用其他存储过程的例子
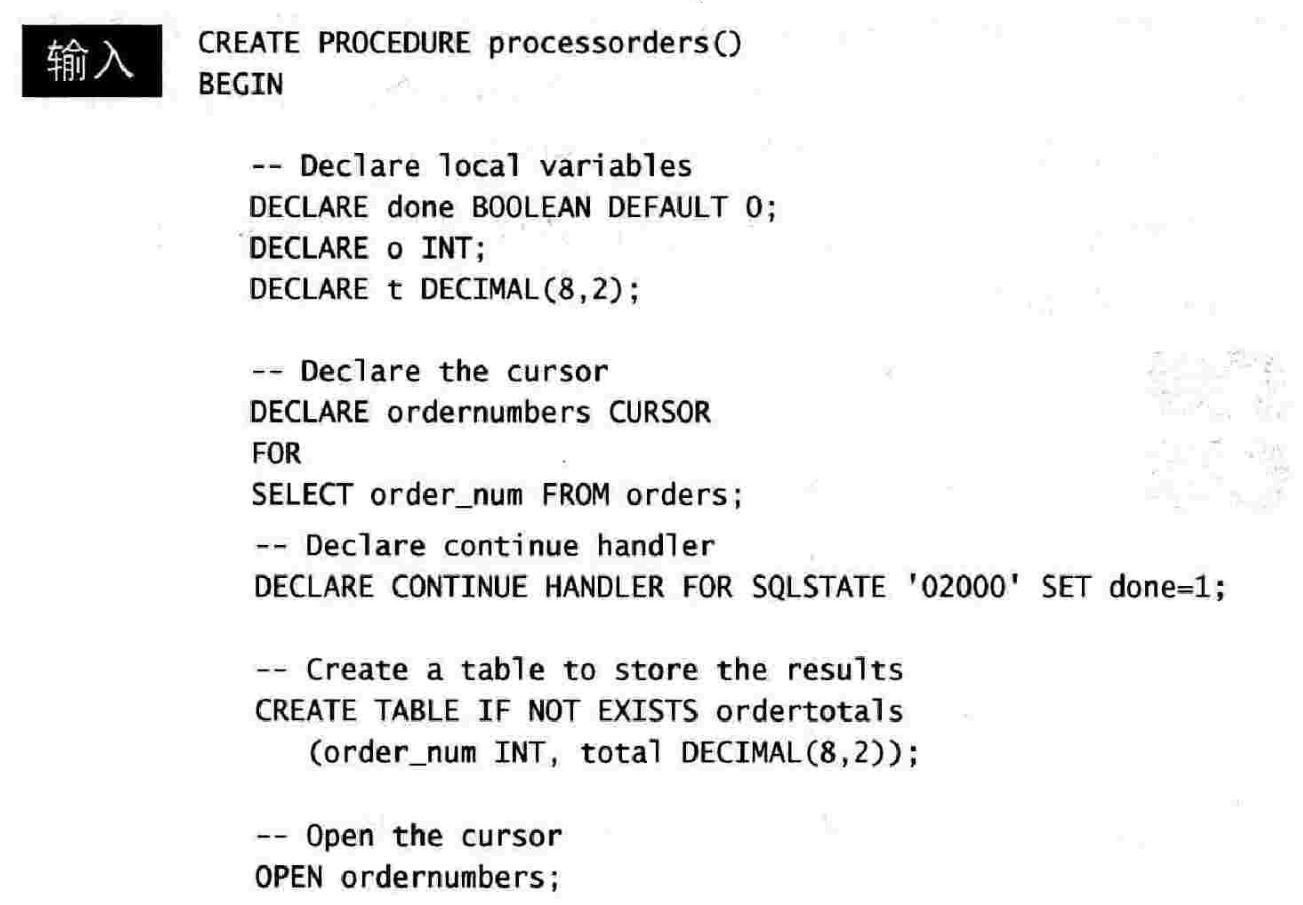
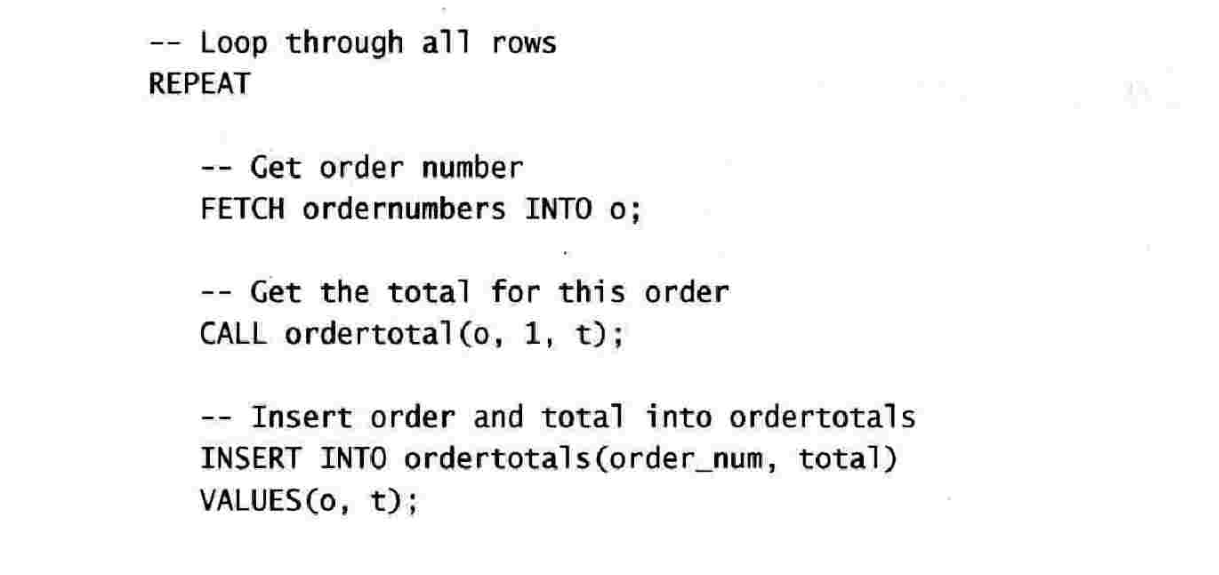

第二十五章 使用触发器
25.1 触发器
触发器是响应一下任意语句而自动执行的一条SQL语句
- DELETE
- INSERT
- UPDATE
其它MySQL语句不支持触发器
25.2 创建触发器

每个表中的触发器名称唯一即可,不要求整个数据库的触发器名称唯一。

只有表支持触发器,视图不支持。
25.3 删除触发器

25.4 使用触发器
25.4.1 INSERT触发器
25.4.2 DELETE 触发器


第二十六章 管理事务处理器
26.1 事务处理(transaction processing)
用来维护数据库的完整性,它保证成批的SQL语句要么全部执行,要么完全不执行

26.2 控制事务处理
管理事务处理的关键是 将SQL语句组分解为逻辑块,并明确规定数据何时应该回退,何时不应该回退。

26.2.1 使用ROLLBACK

26.2.2 使用COMMIT

在事务处理中需要手动提交(COMMIT),否则更改就会被撤销。
26.2.3 使用保留点
保留点用于部分回退

26.2.4 更改默认的提交行为

第二十七章 全球化和本地化
27.1 字符集和校对顺序

27.2 使用字符集和校对顺序
第二十八章 安全管理
28.1 访问控制
28.2 管理用户
mysql> USE mysql
Database changed
mysql> SELECT user FROM user//
+—————————+
| user |
+—————————+
| mysql.infoschema |
| mysql.session |
| mysql.sys |
| root |
+—————————+
4 rows in set (0.00 sec)
查看现有用户
28.2.1 创建用户账号

口令不一定需要

28.2.2 删除用户账号

28.2.3 设置访问权限
查看用户权限:

设置权限:

撤销权限:

28.2.4 更改密码

第二十九章 数据库维护
29.1 备份数据

为了保证所有数据都被写入磁盘,可以在备份之前使用 FLUSH TABLES语句刷新
29.2 进行数据库维护

29.3 诊断启动问题
29.4 查看日志文件

